Vertical Pod Autoscaler (VPA)
Chapter 1- Introduction: Kubernetes Autoscaling
- Chapter 1: Vertical Pod Autoscaler (VPA)
- Chapter 2: Kubernetes HPA
- Chapter 3: K8s Cluster Autoscaler
- Chapter 4: K8s ResourceQuota Object
- Chapter 5: Kubernetes Taints & Tolerations
- Chapter 6: Guide to K8s Workloads
- Chapter 7: Kubernetes Service Load Balancer
- Chapter 8: Kubernetes Namespace
- Chapter 9: Kubernetes Affinity
- Chapter 10: Kubernetes Node Capacity
- Chapter 11: Kubernetes Service Discovery
- Chapter 12: Kubernetes Labels
Vertical Pod Autoscaler (VPA) is a Kubernetes (K8s) resource that helps compute the right size for resource requests associated with application pods (Deployments). This article will explore VPA’s features, provide instructions for using VPA, explain its limitations, and point to an alternative resource optimization approach in conclusion.
The Pod Resource Allocation Dilemma
Consider the sample Kubernetes resource usage dashboard presented in the screenshot below. We can see CPU and memory resources are over-allocated. In other words, the actual usage of those resources is too low compared to the allocated resources. If you are not as familiar with pod resource allocation, you can learn more about it by reading our article about Kubernetes resource limits and requests.
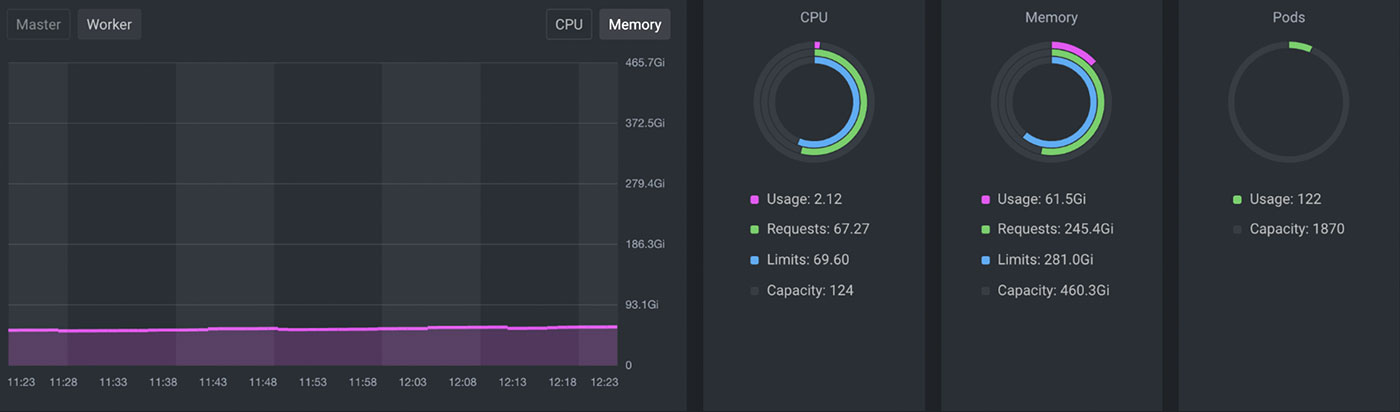
You may encounter this scenario frequently while managing and administering K8s clusters. As a cluster admin, how can you allocate resources more efficiently?
This problem occurs because the Kubernetes scheduler does not re-evaluate the pod’s resource needs after a pod is scheduled with a given set of requests. As a result, over-allocated resources are not freed or scaled-down. Conversely, if a pod didn’t request sufficient resources, the scheduler won’t increase them to meet the higher demand.
To summarize:
- If you over-allocate resources: you add unnecessary workers, waste unused resources, and increase your monthly bill.
- If you under-allocate resources: resources will get used up quickly, application performance will suffer, and the kubelet may start killing pods until resource utilization drops.
The Vertical Pod Autoscaler or VPA functionality provided in the Kubernetes platform aims to address this problem.
Kubernetes Vertical Pod Autoscaler (VPA)
The first reaction to VPA might be, “since legacy stateful applications require expensive refactoring to scale horizontally, let’s instead use a single pod and vertically scale the pod.” Unfortunately, stateful scaling is not yet a supported VPA use case.
How Does Kubernetes Vertical Pod Autoscaler Work?
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 30-day TrialFor simple Deployments or ReplicaSets (that are not stateful), VPA suggests values of requested pod resources and provides those values as recommendations for future Deployments. Alternatively, we can configure VPA to auto-apply those values to our Deployment objects.
How Does Horizontal Pod Autoscaler (HPA) Relate to VPA?
HPA scales the application pods horizontally by running more copies of the same pod (assuming that the hosted application supports horizontal scaling via replication). VPA is still relevant when horizontally scaling as it will compute and recommend the correct values for the requested resources of the pods managed by HPA.
For example, you can use a customized metric such as the number of incoming session requests by end-users to a service load balancer to scale horizontally via HPA. Meanwhile, CPU and memory resource usage metrics can be used separately to adjust each pod’s allocated resources via VPA.
How VPA works
The VPA controller observes the resource usage of an application. Then, using that usage information as a baseline, VPA recommends a lower bound, an upper bound, and target values for resource requests for those application pods.
In simple terms, we can summarize the VPA workflow as:
observe resource usage → recommend resources requests → update resources

Depending on how you configure VPA, it can either:
- Apply the recommendations directly by updating/recreating the pods (
updateMode = auto). - Store the recommended values for reference (
updateMode = off). - Apply the recommended values to newly created pods only (
updateMode = initial).
Keep in mind that updateMode = auto is ok to use in testing or staging environments but not in production. The reason is that the pod restarts when VPA applies the change, which causes a workload disruption.
We should set updateMode = off in production, feed the recommendations to a capacity monitoring dashboard such as Grafana, and apply the recommendations in the next deployment cycle.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 30-day TrialHow to use VPA
Here is a sample Kubernetes Deployment that uses VPA for resource recommendations.
First, create the Deployment resource using the following YAML manifest shown below. Note that there are no CPU or memory requests. The pods in the Deployment belong to the VerticalPodAutoscaler (shown in the next paragraph) as they are designated with the kind, Deployment and name, nginx-deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.8
ports:
- containerPort: 80Then, create the VPA resources using the following manifest:
apiVersion: autoscaling.k8s.io/v1beta1
kind: VerticalPodAutoscaler
metadata:
name: nginx-deployment-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: nginx-deployment
updatePolicy:
updateMode: "Off"Note that the update mode is set to off. This will just get the recommendations, but not auto-apply them. Once the configuration is applied, get the VPA recommendations by using the kubectl describe vpa nginx-deployment-vpa command.
The recommended resource requests will look like this:
recommendation:
containerRecommendations:
- containerName: nginx
lowerBound:
cpu: 40m
memory: 3100k
target:
cpu: 60m
memory: 3500k
upperBound:
cpu: 831m
memory: 8000kYou can set the UpdateMode to auto in the above example to enable auto-update the resource requests (assuming that it’s not being used in a production environment). This will cause the pods to be recreated with new values for resource requests.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 30-day TrialUsing VPA with HPA
As mentioned earlier in this article, you can use both VPA and HPA in a complementary fashion. When used together, VPA calculates and adjusts the right amount of CPU and memory to allocate, while HPA scales the pod horizontally using a custom metric.
Below is an example diagram showing HPA based on Istio metrics. The Istio telemetry service collects stats like HTTP request rate, response status codes, and duration from the Envoy sidecars that can drive the horizontal pod autoscaling. VPA will be driven only by CPU and Memory usage metrics.
The diagram below shows the Kubernetes and Prometheus (monitoring tool) components that come together to enable the use case described above.

VPA Limitations
While VPA is a helpful tool for recommending and applying resource allocations, it has several limitations. Below are ten important points to keep in mind when working with VPA.
- VPA is not aware of Kubernetes cluster infrastructure variables such as node size in terms of memory and CPU. Therefore, it doesn’t know whether a recommended pod size will fit your node. This means that the resource requests recommendation may be too large to fit any node, and therefore pods may go to a pending state because the resource request can’t be met. Some cloud providers such as GKE provide a cluster autoscaler to spin up more worker nodes addressing pod pending issues, but if the Kubernetes environment has no cluster autoscaler feature, then pods will remain pending, causing downtime.
- VPA does not support StatefulSets yet. The problem is scaling pods in StatefulSet is not simple. Neither starting nor restarting can be done the way it’s done for a Deployment or ReplicaSet. Instead, the pods in StatefulSet are managed in a well-defined order. For example, a Postgres DB StatefulSet will first deploy the master pod and then deploy the slave or replication pods. The master pod can’t be simply replaced with just any other pod.
- In Kubernetes, the pod spec is immutable. This means that the pod spec can’t be updated in place. To update or change the pod resource request, VPA needs to evict the pod and re-create it. This will disrupt your workload. As a result, running VPA in auto mode isn’t a viable option for many use cases. Instead, it is used for recommendations that can be applied manually during a maintenance window.
- VPA won’t work with HPA using the same CPU and memory metrics because it would cause a race condition. Suppose HPA and VPA both use CPU and memory metrics for scaling decisions. HPA will try to scale out (horizontally) based on CPU and memory, while at the same time, VPA will try to scale the pods up (vertically). Therefore if you need to use both HPA and VPA together, you must configure HPA to use a custom metric such as web requests.
- VPA is not yet ready for JVM-based workloads. This shortcoming is due to its limited visibility into memory usage for Java virtual machine workloads,
- The performance of VPA is untested on large-scale clusters. Therefore, performance issues may occur when using VPA at scale. This is another reason why it’s not recommended to use VPA within large production environments.
- VPA doesn’t consider network and I/O. This is an important issue since ignoring I/O throughout (for writing to disk), and network bandwidth usage can cause application slow-downs and outages.
- VPA uses limited historical data. VPA requires eight days of historical data storage before it’s initiated. The limited use of only eight days of data would miss monthly, quarterly, annual, and seasonal fluctuations that could cause bottlenecks during peak usage.
- VPA requires configuration for each cluster. If you manage a dozen or more clusters, you would have to manage separate configurations for each cluster. More sophisticated optimization tools provide a governance workflow for approving and unifying configurations across multiple clusters.
- VPA policies lack flexibility. VPA uses a resource policy to control resource computations, and an update policy to control how to apply changes to Pods. The policy functionality is however limited. For example, the resource policy sets a higher and a lower value calculated based on historical CPU and memory measurements aggregated into percentiles (e.g., 95 percentile) and you can’t choose a more sophisticated machine learning algorithm to predict usage.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 30-day Trial
Conclusion
VPA assists in adding or removing CPU and memory resources but its inherent limitations make it too risky to use in a production environment. Optimizing the Kubernetes resources assigned to essential applications requires a holistic optimization of containers, pods, namespaces, and nodes. Machine learning should power such an analysis to avoid human error and scale to support large estates. Another critical factor to consider is the need to consistently apply the same optimization technology to other resources, whether hosted in a public or private cloud. A cross-platform optimization solution reduces the need for organizational training, improves accuracy based on well-established policies, and provides unified reporting. To learn more, read about our holistic approach to optimizing the entire Kubernetes stack.
FAQs
What is Kubernetes VPA?
Kubernetes VPA (Vertical Pod Autoscaler) automatically adjusts pod resource requests for CPU and memory based on historical usage. It helps prevent overprovisioning and underprovisioning in Kubernetes deployments.
How does Kubernetes VPA work?
The VPA controller observes resource usage, recommends lower, target, and upper bounds for CPU and memory, and applies these values to pods. Depending on configuration, changes can be applied automatically, initially, or kept as recommendations.
Can Kubernetes VPA and HPA be used together?
Yes, but not on the same CPU and memory metrics. Kubernetes VPA should handle vertical scaling (CPU/memory), while HPA should be configured with custom metrics such as request counts to avoid conflicts.
What are the limitations of Kubernetes VPA?
Kubernetes VPA doesn’t support StatefulSets, may cause pod restarts in production, only uses eight days of historical data, and ignores network and disk I/O. It can also be difficult to scale across large clusters.
Is Kubernetes VPA recommended for production environments?
In most cases, no. Kubernetes VPA is better suited for testing, staging, or small-scale environments. For production, many teams use VPA in “recommendation mode” and apply the changes manually during maintenance windows.
Try us
Experience automated K8s, GPU & AI workload resource optimization in action.
Try us
Experience automated K8s, GPU & AI workload resource optimization in action.



