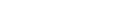Kubernetes Namespace
Chapter 8- Introduction: Kubernetes Autoscaling
- Chapter 1: Vertical Pod Autoscaler (VPA)
- Chapter 2: Kubernetes HPA
- Chapter 3: K8s Cluster Autoscaler
- Chapter 4: K8s ResourceQuota Object
- Chapter 5: Kubernetes Taints & Tolerations
- Chapter 6: Guide to K8s Workloads
- Chapter 7: Kubernetes Service Load Balancer
- Chapter 8: Kubernetes Namespace
- Chapter 9: Kubernetes Affinity
- Chapter 10: Kubernetes Node Capacity
- Chapter 11: Kubernetes Service Discovery
- Chapter 12: Kubernetes Labels
Kubernetes (K8s) namespaces are a way to isolate, group, and organize resources within a Kubernetes cluster.
For many use cases, creating Kubernetes namespaces can help you streamline operations,
improve security, and even enhance performance.
To help you get the most out of Kubernetes namespaces, in this article we’ll take an in-depth look at
what they are, how they work, and when it makes sense to use them. Additionally, we’ll provide some practical
examples you can follow to get hands-on with Kubernetes namespaces.
Kubernetes namespaces: The Basics
Before we jump into the technical details, let’s start with the basics. First, here is
a breakdown of the high-level features and benefits of Kubernetes namespaces (don’t worry, we’ll go deeper in a bit).
| Feature | Benefit |
|---|---|
| Role-based access control (RBAC) per namespace | Enhanced security |
| Resource isolation, Fewer API operations per namespace in large clusters | Improved performance |
| Resource quotas per namespace | Better capacity management |
| Name scoping provided by namespace | Efficient organization |
While those features and benefits are important, they don’t tell you much
about where namespaces fit within Kubernetes architecture. You can think of
namespaces as a type of “virtual cluster” or “sub-cluster” that provide a scope for names
within a Kubernetes cluster. Names of resources need to be unique within a namespace, but not across namespaces.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 60-day TrialHere are a few important concepts to keep in mind when working with namespaces:
- Resources inside namespaces are logically separated from each other but they can still communicate
- Namespaces dont provide true multi-tenancy the way other solutions
do ( such as public cloud virtual infrastructure or Openstack Private Cloud ) - There is a single default Kubernetes namespace, but you can create as many namespaces as needed within a cluster
- Namespaces cannot be nested within each other.
Identifying namespaced Kubernetes resources
Most Kubernetes resources reside in a namespace, but there are some exceptions. For example,
some objects exist at the cluster level and don’t reside in a namespace. To view api-resources and
see which are namespaced in a Kubernetes cluster, you can use the kubectl command.
In our example below, you’ll notice that some resources, like nodes and persistent volumes, are not namespaced.
### Get all the resources, notice the column “NAMESPACED”
$ kubectl api-resources
NAME SHORTNAMES APIGROUP NAMESPACED KIND
bindings true Binding
componentstatuses cs false ComponentStatus
configmaps cm true ConfigMap
endpoints ep true Endpoints
events ev true Event
limitranges limits true LimitRange
namespaces ns false Namespace
nodes no false Node
persistentvolumeclaims pvc true PersistentVolumeClaim
persistentvolumes pv false PersistentVolume
pods po true Pod
podtemplates true PodTemplate
replicationcontrollers rc true ReplicationController
resourcequotas quota true ResourceQuota
secrets true Secret
serviceaccounts sa true ServiceAccount
services svc true Service
mutatingwebhookconfigurations admissionregistration.k8s.io false MutatingWebhookConfiguration
validatingwebhookconfigurations admissionregistration.k8s.io false ValidatingWebhookConfiguration
customresourcedefinitions crd,crds apiextensions.k8s.io false CustomResourceDefinition
apiservices apiregistration.k8s.io false APIService
controllerrevisions apps true ControllerRevision
daemonsets ds apps true DaemonSet
deployments deploy apps true Deployment
replicasets rs apps true ReplicaSet
statefulsets sts apps true StatefulSet
tokenreviews authentication.k8s.io false TokenReview
localsubjectaccessreviews authorization.k8s.io true LocalSubjectAccessReview
selfsubjectaccessreviews authorization.k8s.io false SelfSubjectAccessReview
selfsubjectrulesreviews authorization.k8s.io false SelfSubjectRulesReview
subjectaccessreviews authorization.k8s.io false SubjectAccessReview
horizontalpodautoscalers hpa autoscaling true HorizontalPodAutoscaler
cronjobs cj batch true CronJob
jobs batch true Job
certificatesigningrequests csr certificates.k8s.io false CertificateSigningRequest
backendconfigs bc cloud.google.com true BackendConfig
leases coordination.k8s.io true Lease
endpointslices discovery.k8s.io true EndpointSlice
ingresses ing extensions true Ingress
capacityrequests capreq internal.autoscaling.k8s.io true CapacityRequest
nodes metrics.k8s.io false NodeMetrics
pods metrics.k8s.io true PodMetrics
storagestates migration.k8s.io false StorageState
storageversionmigrations migration.k8s.io false StorageVersionMigration
frontendconfigs networking.gke.io true FrontendConfig
managedcertificates mcrt networking.gke.io true ManagedCertificate
servicenetworkendpointgroups svcneg networking.gke.io true ServiceNetworkEndpointGroup
ingressclasses networking.k8s.io false IngressClass
ingresses ing networking.k8s.io true Ingress
networkpolicies netpol networking.k8s.io true NetworkPolicy
runtimeclasses node.k8s.io false RuntimeClass
updateinfos updinf nodemanagement.gke.io true UpdateInfo
poddisruptionbudgets pdb policy true PodDisruptionBudget
podsecuritypolicies psp policy false PodSecurityPolicy
clusterrolebindings rbac.authorization.k8s.io false ClusterRoleBinding
clusterroles rbac.authorization.k8s.io false ClusterRole
rolebindings rbac.authorization.k8s.io true RoleBinding
roles rbac.authorization.k8s.io true Role
scalingpolicies scalingpolicy.kope.io true ScalingPolicy
priorityclasses pc scheduling.k8s.io false PriorityClass
volumesnapshotclasses snapshot.storage.k8s.io false VolumeSnapshotClass
volumesnapshotcontents snapshot.storage.k8s.io false VolumeSnapshotContent
volumesnapshots snapshot.storage.k8s.io true VolumeSnapshot
csidrivers storage.k8s.io false CSIDriver
csinodes storage.k8s.io false CSINode
storageclasses sc storage.k8s.io false StorageClass
volumeattachments storage.k8s.io false VolumeAttachment
# Get only the resources that are namespaced
$ kubectl api-resources --namespaced=true
NAME SHORTNAMES APIGROUP NAMESPACED KIND
bindings true Binding
configmaps cm true ConfigMap
endpoints ep true Endpoints
events ev true Event
limitranges limits true LimitRange
persistentvolumeclaims pvc true PersistentVolumeClaim
pods po true Pod
podtemplates true PodTemplate
replicationcontrollers rc true ReplicationController
resourcequotas quota true ResourceQuota
secrets true Secret
serviceaccounts sa true ServiceAccount
services svc true Service
controllerrevisions apps true ControllerRevision
daemonsets ds apps true DaemonSet
deployments deploy apps true Deployment
replicasets rs apps true ReplicaSet
statefulsets sts apps true StatefulSet
localsubjectaccessreviews authorization.k8s.io true LocalSubjectAccessReview
horizontalpodautoscalers hpa autoscaling true HorizontalPodAutoscaler
cronjobs cj batch true CronJob
jobs batch true Job
backendconfigs bc cloud.google.com true BackendConfig
leases coordination.k8s.io true Lease
endpointslices discovery.k8s.io true EndpointSlice
ingresses ing extensions true Ingress
capacityrequests capreq internal.autoscaling.k8s.io true CapacityRequest
pods metrics.k8s.io true PodMetrics
frontendconfigs networking.gke.io true FrontendConfig
managedcertificates mcrt networking.gke.io true ManagedCertificate
servicenetworkendpointgroups svcneg networking.gke.io true ServiceNetworkEndpointGroup
ingresses ing networking.k8s.io true Ingress
networkpolicies netpol networking.k8s.io true NetworkPolicy
updateinfos updinf nodemanagement.gke.io true UpdateInfo
poddisruptionbudgets pdb policy true PodDisruptionBudget
rolebindings rbac.authorization.k8s.io true RoleBinding
roles rbac.authorization.k8s.io true Role
scalingpolicies scalingpolicy.kope.io true ScalingPolicy
volumesnapshots snapshot.storage.k8s.io true VolumeSnapshot
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 60-day Trial
Why Kubernetes namespaces are important
There are many reasons why you will need to use separate namespaces instead of placing all resources
in a single (default) namespace. At a high level, using a single namespace can create naming conflicts
for Kubernetes resources like deployments, services, and other objects.
These conflicts can lead to problems such as environment variables and secrets being visible
across different application pods. Using namespaces can help you avoid these problems.
When to use Kubernetes namespaces
With that in mind, let’s take a look at some common use cases for Kubernetes namespaces.
- Large teams can use namespaces to isolate their microservices.
Teams can re-use the same resource names in different workspaces without conflicts.
Additionally, taking action on items in one workspace never affects other workspaces. - Organizations that use a single cluster for development, testing, and production can use
namespaces to isolate environments. This practice ensures production code is not affected by changes
that developers make in their own namespaces. - Namespaces enable the use of RBAC, so teams can define roles that group lists of permissions.
RBAC can ensure that only authorized users have access to resources in a given namespace. - Users can set resource limits on namespaces by defining resource quotas. These quotas can
ensure that every project has the resources it needs to run and that one
namespace is not hogging all available resources. - Namespaces can improve performance by limiting API search items. If a cluster
is separated into multiple namespaces for different projects, the Kubernetes API
will have fewer items to search when performing operations. As a result, teams
can see performance gains within their Kubernetes clusters.
Working with Kubernetes namespaces
Now that we’ve covered what namespaces are and when to use them, let’s jump into working with them.
The default namespaces in Kubernetes
Most Kubernetes distributions will create three namespaces by default. You can see
these default Kubernetes namespaces when you create a new cluster by using kubectl command.
$ kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-public Active 1d
kube-system Active 1d
Here is a breakdown of what each of those automatically created namespaces is:
- default- used by user apps by default, until there are other custom namespaces
- kube-public- used by public Kubernetes resources, not recommended to be used by cluster users
- kube-system- used by Kubernetes control plane, and must not be used by cluster users
Creating and deleting Kubernetes Namespaces
You can use the kubectl create command or kubectl apply/create
with a YAML manifest to create Kubernetes namespaces. For listing namespaces, use kubectl get command.
Get the list of current namespaces:
$ kubectl get namespaces
NAME STATUS AGE
cert-manager Active 158d
default Active 678d
gitlab-managed-apps Active 678d
kube-node-lease Active 678d
kube-public Active 678d
kube-system Active 678d
monitoring Active 653d
wordpress Active 675d
wordpress-stage Active 304d
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 60-day TrialCreate a new namespace called “test”:
$ kubectl create namespace test
namespace/test created
## OR using the yaml
$ cat test.yaml
apiVersion: v1
kind: Namespace
metadata:
name: test
$ kubectl create -f test.yaml
namespace/test created
See the new namespace is created by getting the new updated list:
$ kubectl get ns
NAME STATUS AGE
cert-manager Active 158d
default Active 678d
gitlab-managed-apps Active 678d
kube-node-lease Active 678d
kube-public Active 678d
kube-system Active 678d
monitoring Active 653d
test Active 17s
wordpress Active 675d
wordpress-stage Active 304d
Finally, delete the namespace
$ kubectl delete ns test
namespace "test" deleted
Note: Be careful with namespace deletion, as everything inside the namespace will also be deleted.
Kubernetes namespaces and the kubectl context
The default kubectl context points to the namespace “default”. When you work
with a cluster that has multiple namespaces, you will need to switch context to work with
each namespace. You can switch between namespace contexts using this command:
kubectl config set-context --current --namespace=<insert-namespace-name-here>You can validate that the command worked with this command:
kubectl config view --minify | grep namespaceCreating, listing, and deleting resources inside namespaces
When the current context is not pointing to the namespace you are working with, you can use
the namespace flag to make sure your command is launched against your desired namespace.
First, create an app in test namespace:
$ kubectl run nginx --image=nginx --namespace=testSpend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 60-day TrialWhen you use the kubernetes yaml to create a deployment , you can use the metadata section to
specify the namespace in which the deployment and its resources/pods should be created. For example:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: test
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
To get a list of pods in test namespace:
$ kubectl get pods --namespace=test
To get a list of pods in all namespaces:
$ kubectl get pods --all-namespaces
Namespaces and Resource Quotas
You can implement Resource Quotas on a namespace so that cluster resources are allocated
the way you need them to be. You can define a resource quota object
on your desired namespace. For example, this manifest will create a CPU quota for the namespace demo.
apiVersion: v1
kind: ResourceQuota
metadata:
name: test-cpu-quota
namespace: demo
spec:
hard:
requests.cpu: "200m"
limits.cpu: "300m"
This means that once the quota is created, pods
created and running inside the demo namespace will be limited to the above requests and limits.
Once the limit is reached, no more pods can be created inside the demo namespace.
Namespace and Kubernetes DNS/service discovery
Kubernetes services that are defined in separate namespaces can’t directly talk to
each other using short names the way they do inside the same namespace. For cross-namespace communication,
will need to use fully qualified domain names (FQDNs) so that the name contains the namespace qualifier.
Conclusion
Namespaces are a powerful mechanism for isolating Kubernetes resources. With a solid understanding of
how they work, you can use Kubernetes namespaces to enhance security, simplify management, and improve cluster performance.

Instant access to Sandbox
Experience automated Kubernetes resource optimization in action with preloaded demo data.
Instant access to Sandbox
Experience automated Kubernetes resource optimization in action with preloaded demo data.