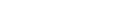OpenShift Serverless: Guide & Tutorial
Guide to OpenShift Tutorial January 11, 2023
January 11, 2023 Cloud-native deployment strategies focus on code and less on the underlying infrastructure than legacy
deployment models. Serverless computing takes that code focus to the extreme by abstracting away backend
services and only invoking them when necessary.
The core benefit of serverless is simplifying from code to application launch. Because developers don’t
have to worry about infrastructure, they can focus on coding business logic that delivers value to end
users.
This article will explore what it means to be serverless (hint, there are still servers) and highlight
the benefits and potential pitfalls of an event-driven serverless deployment model.Then, we will look at
the popular Red Hat OpenShift Serverless model. OpenShift Serverless uses Knative to integrate
serverless features on top of flexible OpenShift infrastructure.
Serverless vs. Other Deployment Models
Before deep diving into the serverless world, let’s compare it to other popular deployment models. As
shown in the table below, serverless allows developers to minimize the server resources they use
relative to other deployment models.
Serverless vs. Other Deployment Models
| Technology | Description |
|---|---|
| Servers | Running an application on a physical server requires continuous resource consumption. Scaling out is slow and involves demand forecasting. |
| VMs | Virtual Servers (VMs) achieve better resource utilization because they can be sized to fit the workload requirements regardless of the size of the underlying infrastructure. |
| Containers | Containers allow for more efficient resource utilization than VMs. For one reason they do not contain an OS per container. They have a smaller resource footprint, and container orchestration makes scaling up or down easier. |
| Serverless | All the benefits of containers with regards to resource utilization but once the application’s function has completed, resources are released. A serverless model can quickly scale up and down as needed. |
What Does It Mean to be Serverless?
Let’s get this out of the way first: serverless does not mean the absence of servers. Serverless
is an architecture model for running applications in an environment that is abstracted away from the
developers.
With serverless computing, developers can focus more on developing their applications than where their
code runs. In other deployment models, resources wait idly to serve requests and run regardless of
whether there is work to do.
One of the concerns with a serverless model is the idea of the cold start. When using serverless, there
is a period between the request and creating the pod environment. This period is the cold start.
Cold starts are an inherent problem with “on-demand” resource consumption because they can generate
latency in response times. Developers can address this problem by ensuring their applications do not
take an extended time to spin up.
What is OpenShift Serverless?
OpenShift Serverless is a way to run serverless workloads while maintaining control over how an
application is built and deployed. With OpenShift, the same serverless platform can be used on-premise,
in the cloud, or hybrid environments.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 60-day TrialExamples of Serverless Workloads
OpenShift Serverless workloads follow this workflow:
- A request comes in
- A pod is spun up to service the request
- The pod services the request
- The pod is destroyed
That workflow makes serverless ideal for some use cases, and suboptimal for others.
The ideal serverless workload executes a single task. For example, a function that retrieves data from a
database can be an excellent serverless workload. However, the database server is not a good serverless
workload because it needs to run continuously.
Another superb example of a serverless workload is an image processing function. An event could be a
photo upload. The uploaded photo triggers an event to run an application to process the image. For
example, the application may overlay text, create a banner, or make a thumbnail. Once the image is
stored permanently, the application has served its purpose and is no longer needed.
Features of a Serverless Model
These are the top features of a serverless model.
Serverless Features
| Feature | Description |
|---|---|
| Stateless functions | The ideal application is a single purpose and stateless function. For example, a function to query a database and return the data. |
| Event Driven | A serverless model relies on a trigger to execute the code. This could be a request to an API or an event on a queue. |
| Scale to Zero | Being able to scale to zero means your code only runs when it needs to respond to an event. Afterward, resources are released. |
Benefits of serverless
Every evolution of a deployment model has advantages over previous methods. Usually, these benefits are
cost savings and more efficient utilization of CPU, RAM, and storage resources. The table below compares
serverless resource utilization to servers and VMs.
Serverless vs. Servers / VMs
| Category | Serverless | Servers / VMs |
|---|---|---|
| Cost | Code is executed as needed. There is no idle time. If no requests are coming in, you are not paying for anything. You pay for execution time. |
A server is always running 24/7 regardless of whether requests are coming in or not. You pay for the infrastructure running 24/7, and it is costly to expand. |
| Infrastructure Management | There are no servers to manage. No patching or security updates are needed. No monitoring is required. |
Servers/VMs need to be patched for bug fixes and security issues. Monitoring is also usually required. |
| Scalability | Because the underlying platforms have generally plentiful resources, scaling is easier when running serverless. There is less need to be concerned about the capacity for scaling. |
Scalability requires more planning when running servers or VMs. Often, there is a resource limit to how many instances of an application can grow. |
| High Availability | The responsibility to make things high-availability is on the side of the platform. The code can be executed as many times as needed simultaneously. |
Similar to scalability, high availability must be a design choice when deploying the server/VM environment. |
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 60-day TrialKnative and OpenShift Serverless
Red Hat’s OpenShift Serverless is based on the CNCF
Knative project. Knative provides a serverless application layer on top of OpenShift/Kubernetes.
WIth Knative and OpenShift, developers get the best of both worlds. They can focus on their code because
the infrastructure is abstracted away, and sysadmins can focus on infrastructure management instead of
troubleshooting why specific code will not run.
Knative consists of three building blocks. These are the components that allow for serverless workloads
to run on OpenShift.
- Build – Because you are building on top of OpenShift, the developer tools and
templates built into OpenShift are available when building your pod for serverless. - Eventing – Part of being serverless is consuming and reacting to events. Eventing
ties into pipelines to use events on those pipelines to trigger events. This could be a Kafka
pub/sub model or a Jenkins CI/CD build. - Serving – Openshift serverless can scale from ‘N’ to 0 and back up to ‘N’ again
according to demand. It uses Istio for intelligent traffic routing
and management.
To better visualize how easy it is to get OpenShift Serverless installed via an operator, the next
section will walk through installing the OpenShift Serverless operator and creating instances of Knative
Server and Knative Eventing.
The OpenShift Serverless Operator
You can easily install Knative using the OperatorHub in your OpenShift web console.
Step 1. In the left-hand menu, navigate to the OperativeHub, search for the
knative operator and click on Red Hat OpenShift Serverless.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 60-day Trial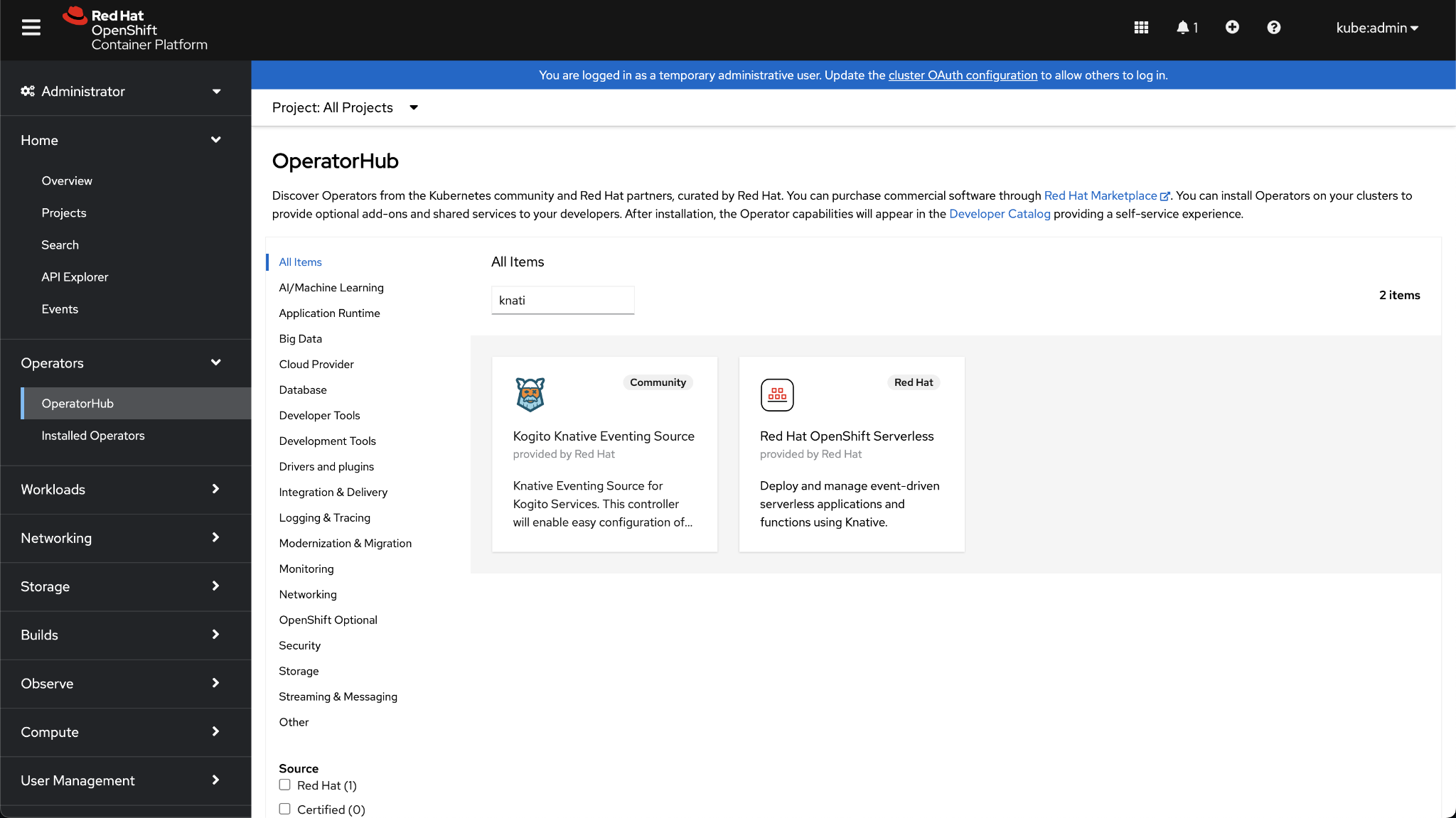
Step 2. On the next screen, click Install.
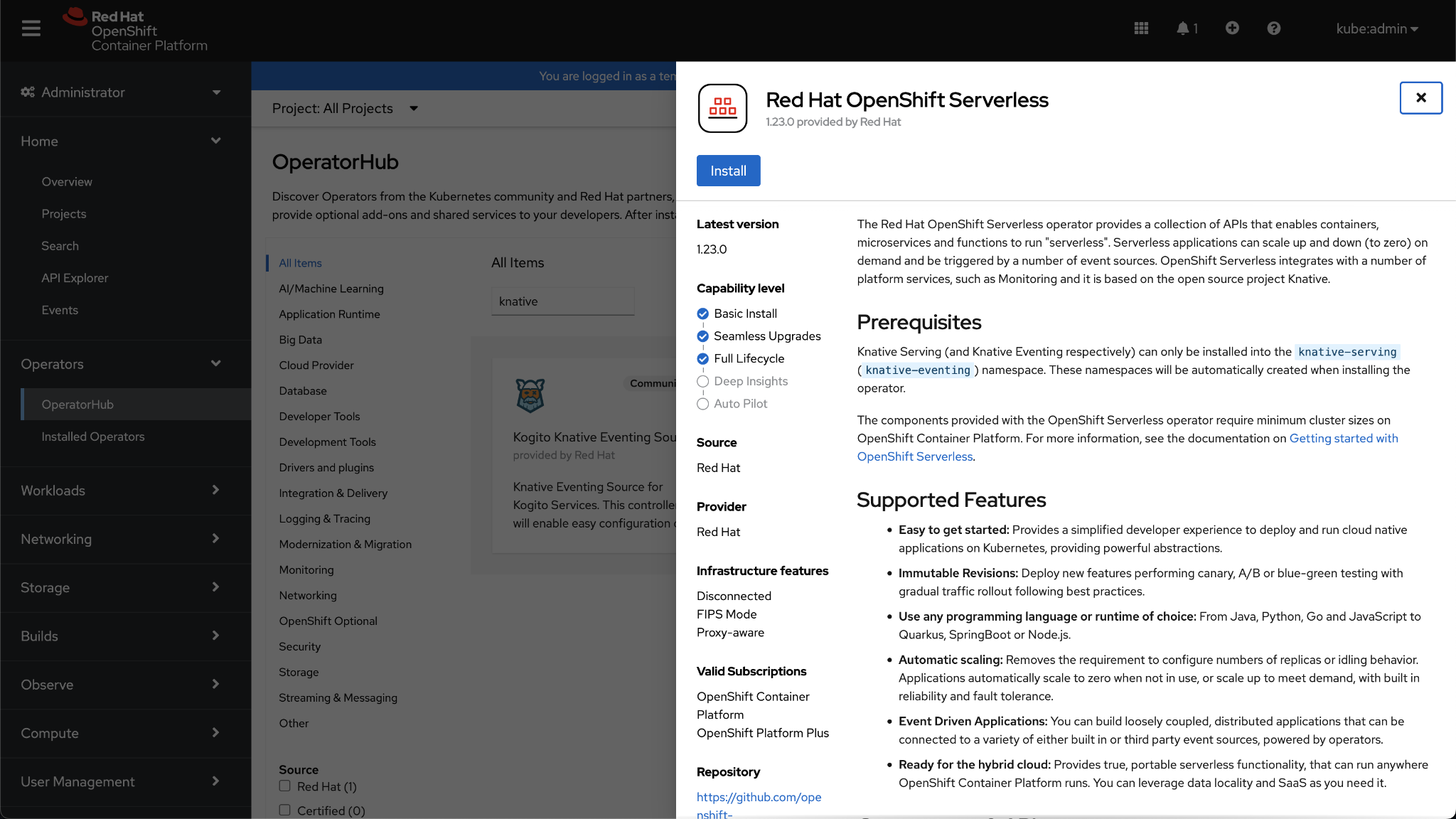
Step 3. Leave the defaults and click Install again.
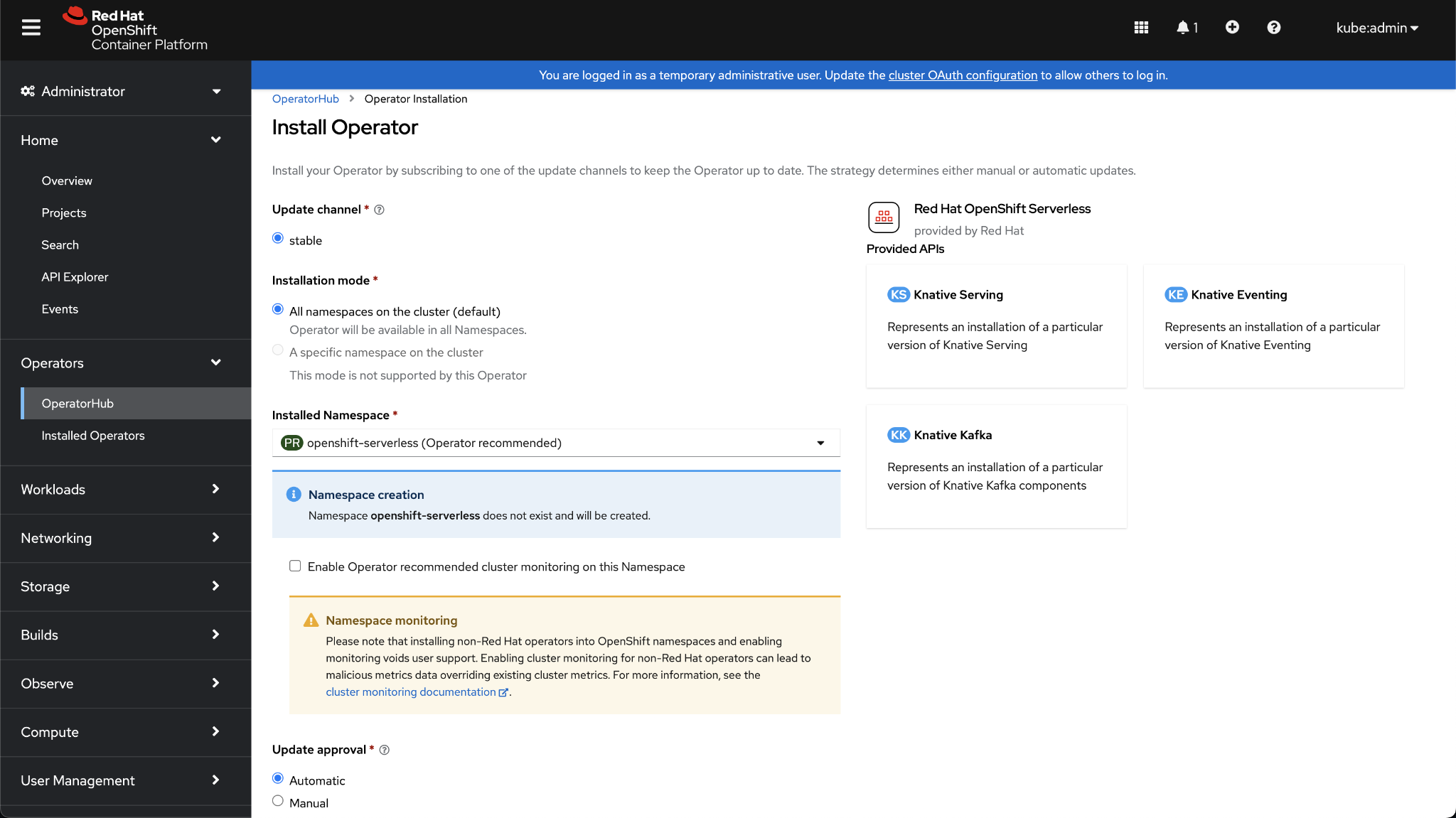
Step 4. Verify the Operator is installed by clicking on Installed Operators in
the left-hand menu.
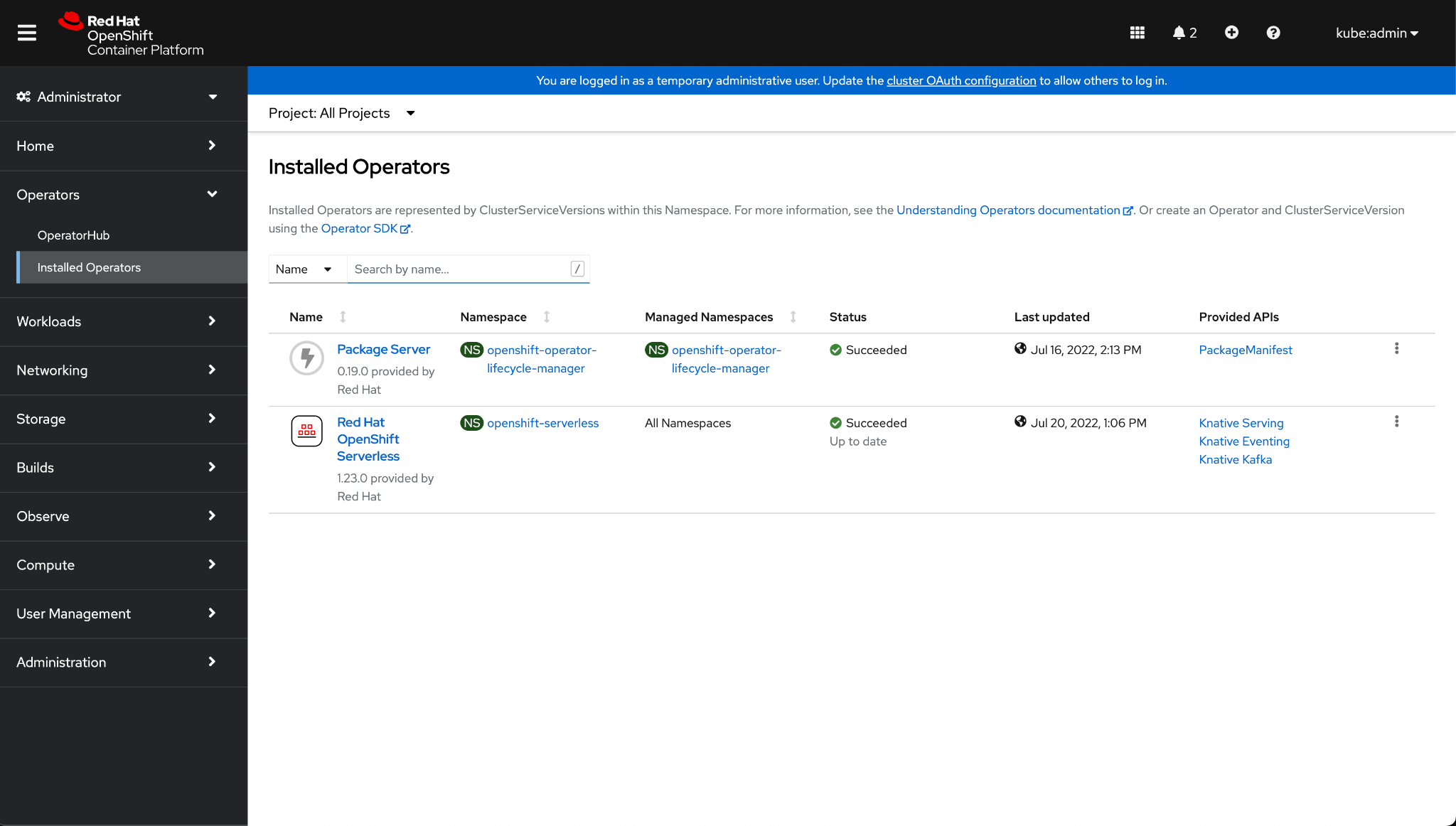
Step 5. Click on Red Hat OpenShift Serverless.
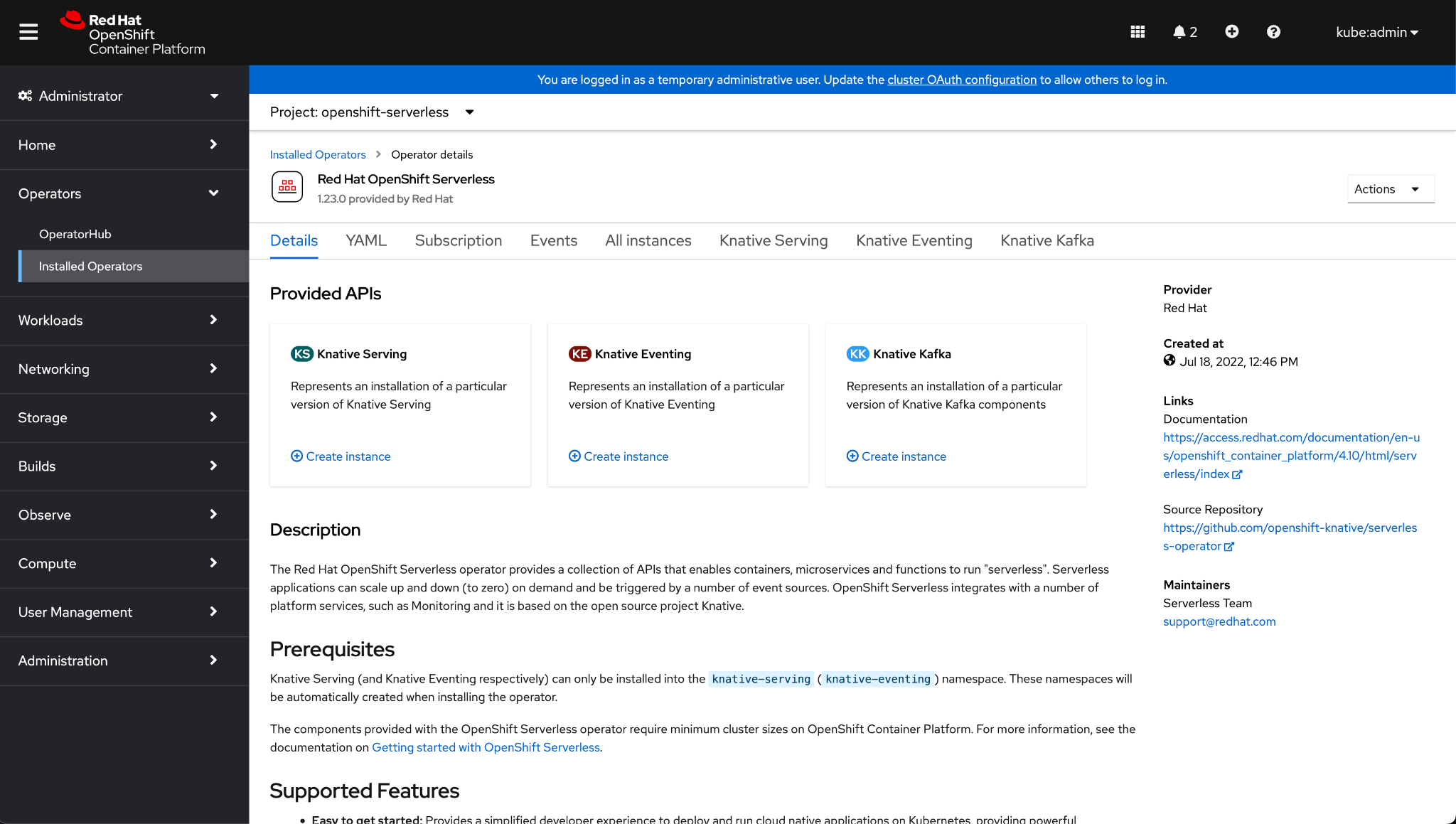
Now, Knative is installed. The next step is to create an instance of knative eventing and knative
serving.Step 6. Select the knative-serving project from the drop-down panel.
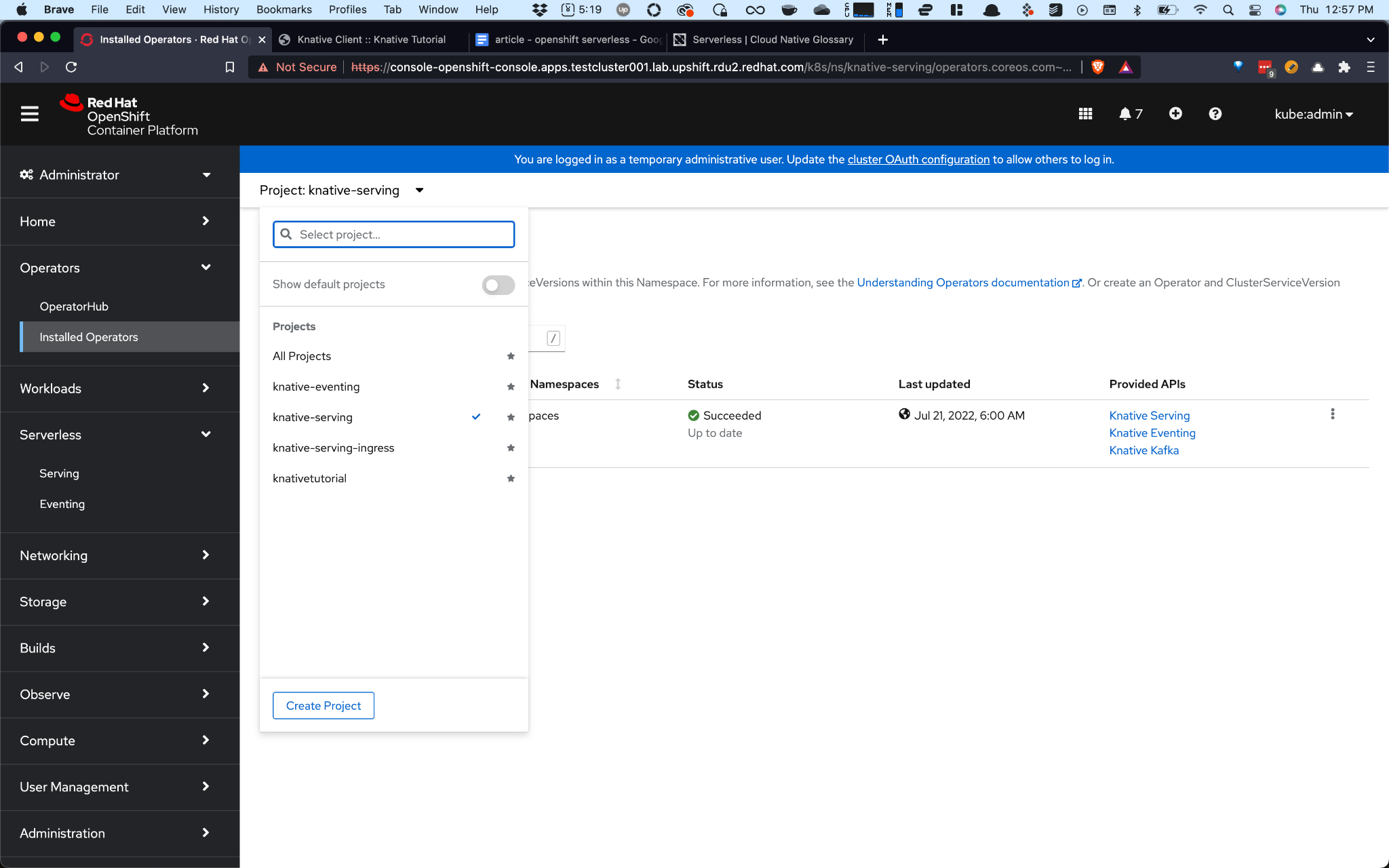
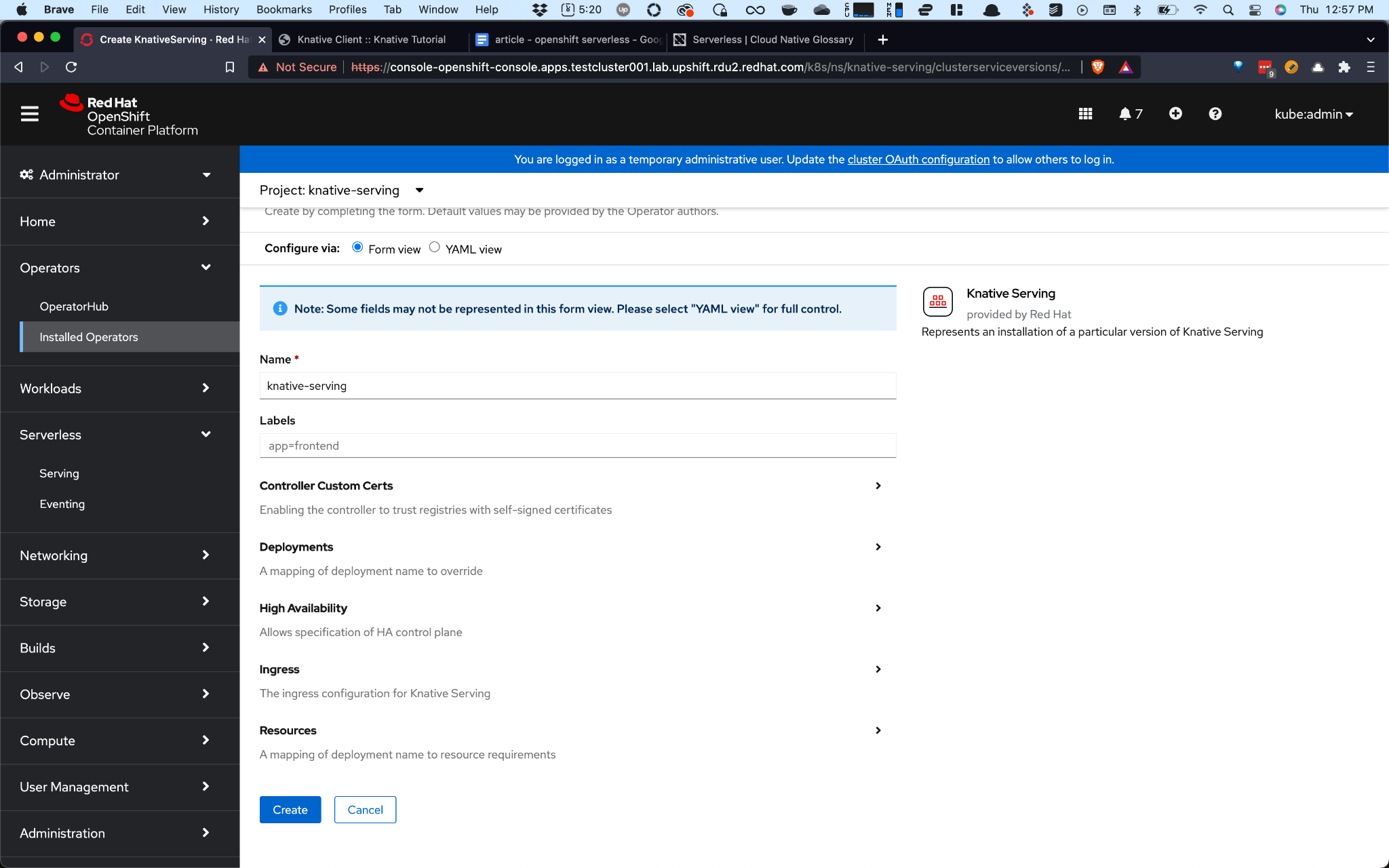
Step 7. Click on Create Instance under Knative Serving
Step 8. Leave the defaults as-is and click on Create.
Step 9. Repeat the same steps for Knative Eventing.
- Switch to the knative-eventing project
- Click on Create Instance under Knative Eventing
- Accept the defaults and click Create
Once complete, your OpenShift Serverless install is ready to work through tutorials
or launch your workload.
OpenShift Serverless Alternative: Functions as a Service
The serverless model is often associated with Function as a Service (FaaS). Most cloud providers offer
some version of serverless through FaaS.
Both Functions as a Service and Red Hat OpenShift Serverless are implementations of a serverless model.
The trade-off is control. Using one serverless model from a major provider will implement more
restrictions than implementing serverless on top of an infrastructure you fully control.
Amazon has Lambda, Google has Cloud Functions, and Azure has Functions.
FaaS features are common amongst the major providers. They all allow for the serverless model of only
paying for the time you are using.
When looking at alternatives, consider each provider’s limitations on your functions. For example,
because these are multi-tenant services, your applications have a time limit on how long they can run.
| AWS Lambda | Google Cloud Functions | Azure Functions | |
| Time Limit | 15 Minutes | 60 minutes for HTTP functions. 10 minutes for event-driven functions. | 10 Minutes |
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 60-day TrialConclusion
Serverless is an exciting evolution for cloud-native application deployments. While the serverless
moniker can be misleading, the benefits are real. Public cloud serverless implementations like AWS
Lambda completely abstract away hardware but come with tradeoffs in the form of vendor lock-in and
lack
of control. OpenShift serverless balances the benefits of a developer-focused workflow and the
flexibility of managing on-premise, cloud, or hybrid environments and resources.