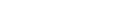The Benefits of Integrated FinOps and Resource Analytics
Learn 4 steps to solve cloud efficiency challenges with FinOps and Accenture – watch the 20-min webinar video.
In this article we will cover:
- FinOps Foundation 2024 survey results
- The cost challenge
- What is Densify?
- Selecting the right infrastructure
- How Densify works
- Optimization vs Control
- Cloud Resource Optimization
- The evidence: App owner report
- Taking recommendations
1. FinOps Foundation 2024 survey results
The FinOps Foundation states that “For the first time, Reducing waste was the highest key priority for FinOps practitioners across all spending tiers. This may be influenced by macroeconomic trends, with businesses looking for ways to reduce spending without reducing the value they are getting from their cloud investments.”
Read the complete 2024 FinOps Foundation survey results report linked here.
Looking at the recent survey results we see that there is a big focus on waste reduction. I have noted a few other challenges that rated highly and are highly related to reducing waste.
2. The cost challenge
If you look at the overall challenge of cost control in cloud, you can break it down into two major chunks: What you are paying (rate) and how much you are consuming (resources). Once commitments have been made and negotiations done on rate, the harder part is dealing with actual infrastructure optimization to reduce wasted resource consumption.

Both parts are large contributors to cost control, however much of what gets focused on is the rate and commitments because those don’t involve making change to infrastructure. Over time this becomes harder to make improvements upon. Eventually you must turn to infrastructure efficiency to find savings.
3. What is Densify?
Densify is AI-driven analytics designed to optimize cloud and container resources. not just for cost, performance as well. We understand a business driver for this is a really large bill, so that tends to be a big focus and we do it across the major cloud providers: AWS, Azure and Google Cloud Platform. We also cover Kubernetes On-prem: OpenShift.
Let’s focus on cloud optimization and take a look at some examples from Amazon, Azure and Google Cloud Platform(GCP) to make the point that we do cover all three major providers.
4. Selecting the right infrastructure
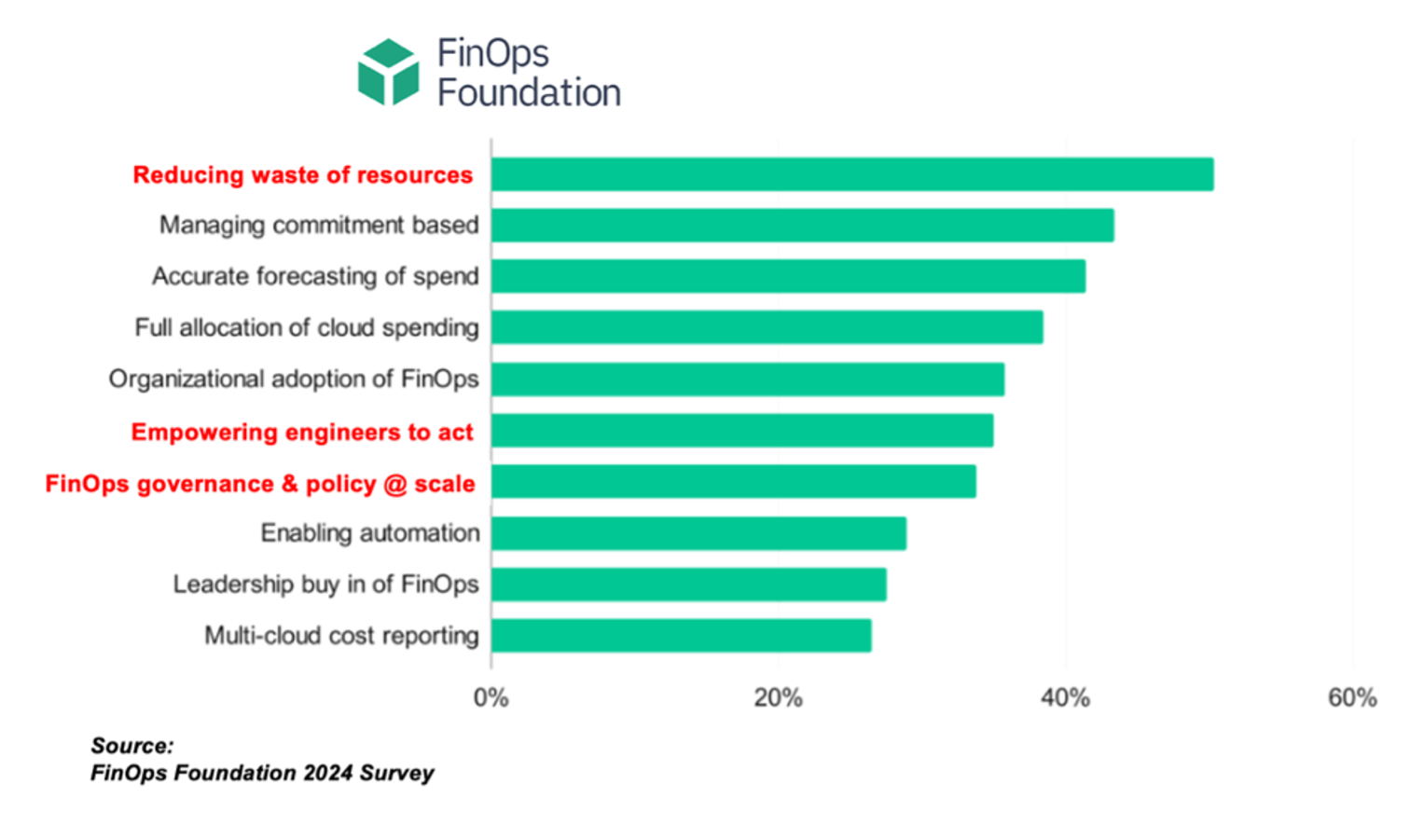
The challenge is, from our perspective as cloud optimization specialists, is that it could be very difficult to pick the right instance for any given workload. For example, lets say you have a workload, it could be a web server, database server, whatever and it is, running on an M3 XL – that’s a pretty old instance. It’s probably not the best one for your workload, given all the newer stuff out there and it was a 4×16. Now, what do I do to optimize this? Where can I go?
This is where it starts to get really complicated. There is an M1 in the catalog, but you’re not going to go backwards. There is an M2 as well, but it’s been discontinued, and it wasn’t really even an M, it was more of a high memory instance. There’s an M4 XL, which obviously looks like a great progression.
But there’s a bunch of differences in it, Ie. paravirtualization, classic networking, you lose your local disk. So if you go to EBS, can it handle what you were doing on your local disk? This are where it starts to get tricky. And this is exactly what Densify focuses on. We have a very deep policy engine that will tell you that if you’re on an M3 and you’re using your local disk, maybe you shouldn’t go to an M4.
As time progresses, of course, in the case of Amazon and all the providers, there are more and more differentiated offerings. For example, there’s an M5 which requires different drivers. Or an M5ZN, which actually has really fast per core performance. So it’s not an M either, but it’s really great for certain workloads; it’s a bit of a minefield to figure out which one to move your workload on. And that’s exactly what Densify focuses on: optimizing the instance selection through very deep analytics.
Now, we’re still not done because it may be that you’re better off on a memory optimized or burstable. And the bottom line is that as there are many more offerings in the cloud – the odds are there’s the exact right one for your workload, but it’s very difficult to figure that out without the right analytics, not to mention that it even varies by region, meaning even if you think you have the right one, it might not be in the region that you’re in.
5. How Densify works
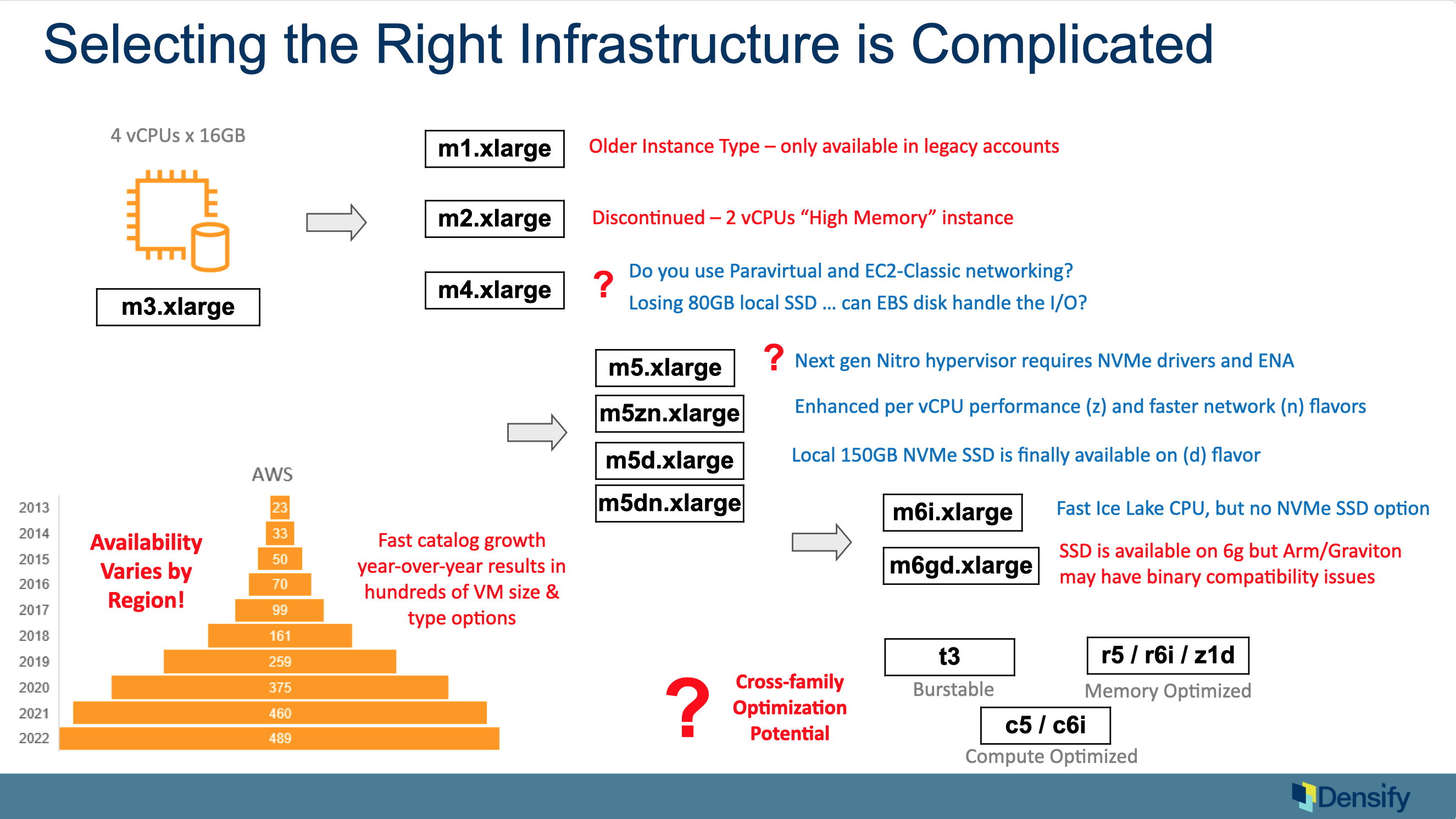
The way Densify solves these challenges is through our deep analytics. We start by getting the utilization data metrics from the providers. It’s agentless for cloud; it just use the APIs. For containers there is a forwarder that’s required. And we apply machine learning on these patterns to figure out: what are the meaningful patterns and levels of activity in this environment?
For example, one of our main algorithms will go back through time and say, between midnight and 1 am, what typically happens in this workflow; what happens at 1 to 2 am? or 2 to 3 am? And we have a learning period to say, based on enough data, we can converge on a pattern saying this is what this thing typically does and this is its peak and sustained activity.
We also build out busiest day models, quarter end, etc. We build a series of models to characterize the workload and this is key to figuring out what it should run on. Obviously, the level is important as well as the shape of it is also important Ie. the composition of the workload. Densify does this for CPU, Memory, all the IO characteristics to get a very deep model that is geared towards figuring out what we should run this thing on.
We recognize that it is very difficult to do this by looking at a Grafana or typical type of utilization curve screen because the peaks and valleys don’t make much sense. Densify provides a much more advanced pattern model of what’s happening in an environment.
We also get the configuration details: how many NICs, HBAs. Our policies apply to all of these. We can even detect running software to say, that thing is running TensorFlow and we can put it on this CPU that has an accelerator. We also cover tags. With all of this information we get a very detailed model of the demand in the cloud. And then we analyze it against the entire cloud catalog.
In the case of an Amazon, it would look a bit like this, where we’re saying, this is all the offering that Amazon has (however for the purpose of this example this actually isn’t all of it); this is the commonly used offering in Amazon.
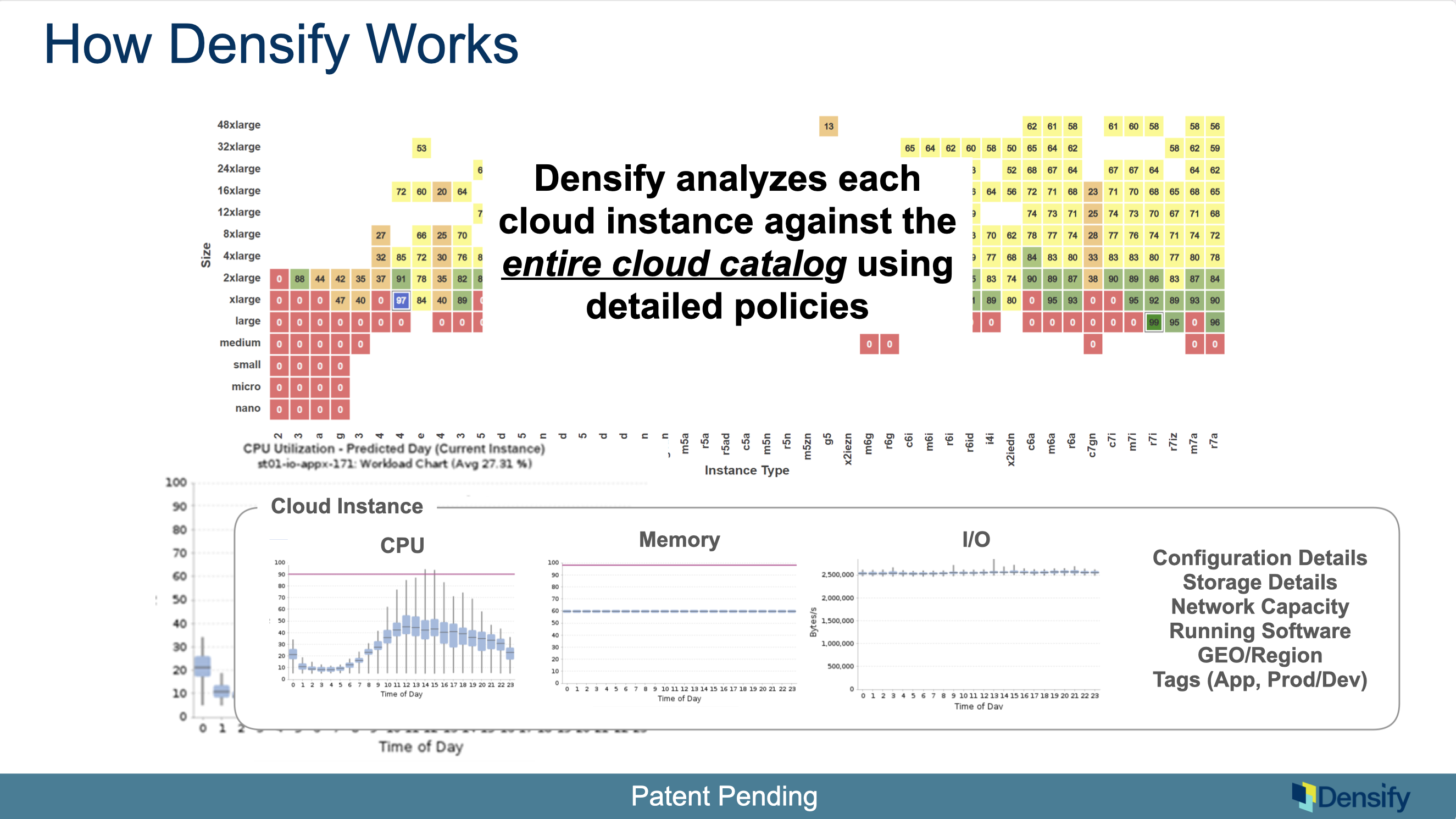
How does this workload score against all those instances? And which one should I be using? This highlights a very deep analysis based on very deep models to come up with a very well informed answer of what you should do/actions should be taken.
Now let’s explore this map in more detail. We nicknamed this the “periodic table”. The way you read this is map is: across the bottom (x-axis) are all the instance families and up the side (y-axis) are all the sizes.
Here you currently running on an M4 extra large (current instance). And we’re saying, well, you know what, you can run on an R7i large (optimal instance).
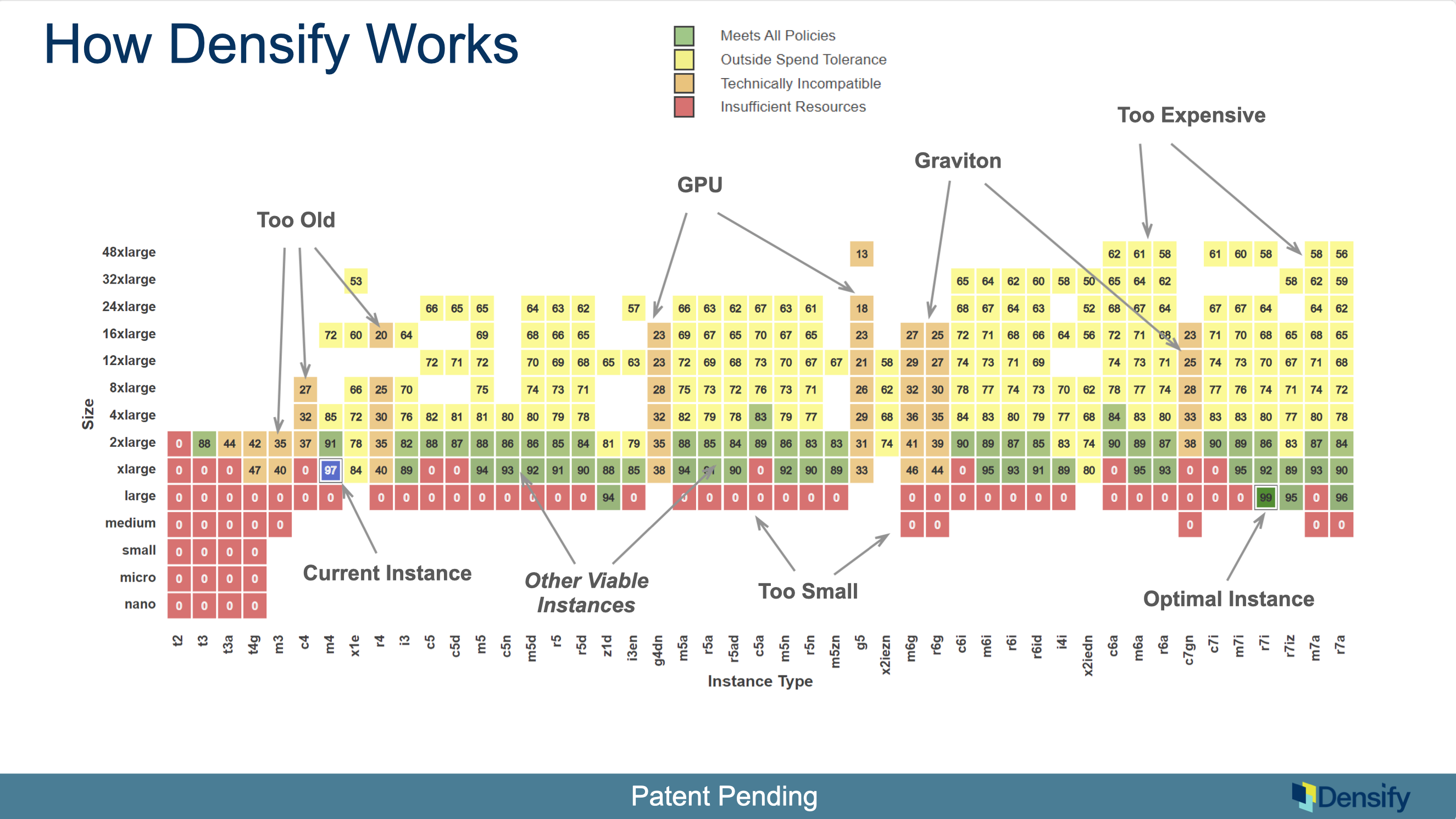
Red is insufficient resources: the ones that you can’t run on because they don’t have enough memory or CPU or IO bandwidth; and the fact that we’re down a level to the right is kind of Moore’s Law in action. The newer ones are so much faster, you can get by on a smaller size. And you could in a Gen 4, Gen 5 type of scenario. So, the red is the stuff that’s just not big enough to fit you.
Orange is technically incompatible: failing the rule/the policy engine. We don’t want to go on to something really old. We might have a policy saying let’s not stay on 10 year old. These ones are running a different CPU architecture so your app might not work if you go into those. This is a rule that you can use or lift depending on the workload. If you have local storage, then all the ones that don’t have local storage would show up as orange stripes as well. A detailed analysis of what you can and can’t run on from a technical perspective.
Yellow is outside spend tolerance: technically viable, but not wise from the cost angle. Here we’re saying those things will technically work but they’re just too expensive. The dividing line between the yellow and the green, you can control through what we call a spend tolerance policy.
Green meets all policies: the optimal one; all the green ones will work within the certain spend tolerance.
6. Optimization vs Control
The two main ones are what we call cloud resource optimization and cloud resource control.
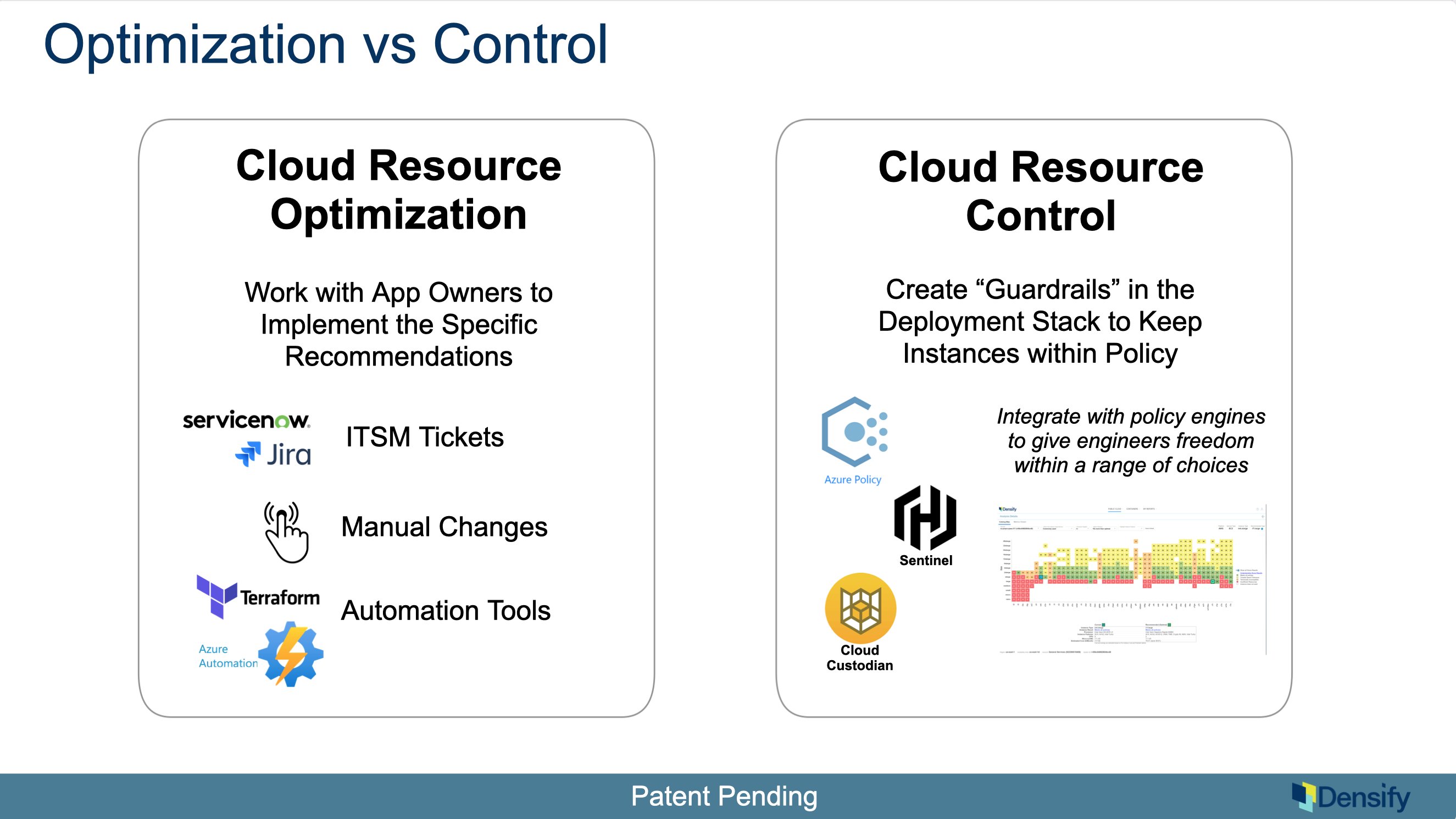
1. Cloud Resource Optimization
When we’re telling you that the best one is an R7i large, just make it an R7i large; and there’s various ways to do that. You can open change tickets via ServiceNow or Jira. You can do Terraform integration; Densify has a very sophisticated way of doing this with Accenture to campaign around this and get the app teams to enact that recommendation and there are huge benefits on that Ie. it’s probably going to work better, it’s going to be cheaper, and that’s the holy grail back to that FinOps Foundation survey. This, in our view, is the path to solving that top challenge: to drive out waste effectively with accurate answers that are implemented by the teams.
2. Cloud Resource Control
The other way we’ll talk a bit more about is a newer way that we refer to as Cloud Resource Control.
In this case, we’re not actually making it the best one, but rather focusing on making sure you stay in that green area, the set of choices that are optimal, and integrating with policy engines. The point is to not be too prescriptive and and tell them what to do but rather: you can do what you want BUT I will warn you if you’re running something that’s too expensive or doesn’t have a disk or it’s too small.
This is a newer way to enforce control, which we find is interesting because it means you can engage in a different way with application teams to take action. Instead of hounding them with reports, you can just put in place a policy engine that’s going to warn them in their tooling.
7. Cloud Resource Optimization
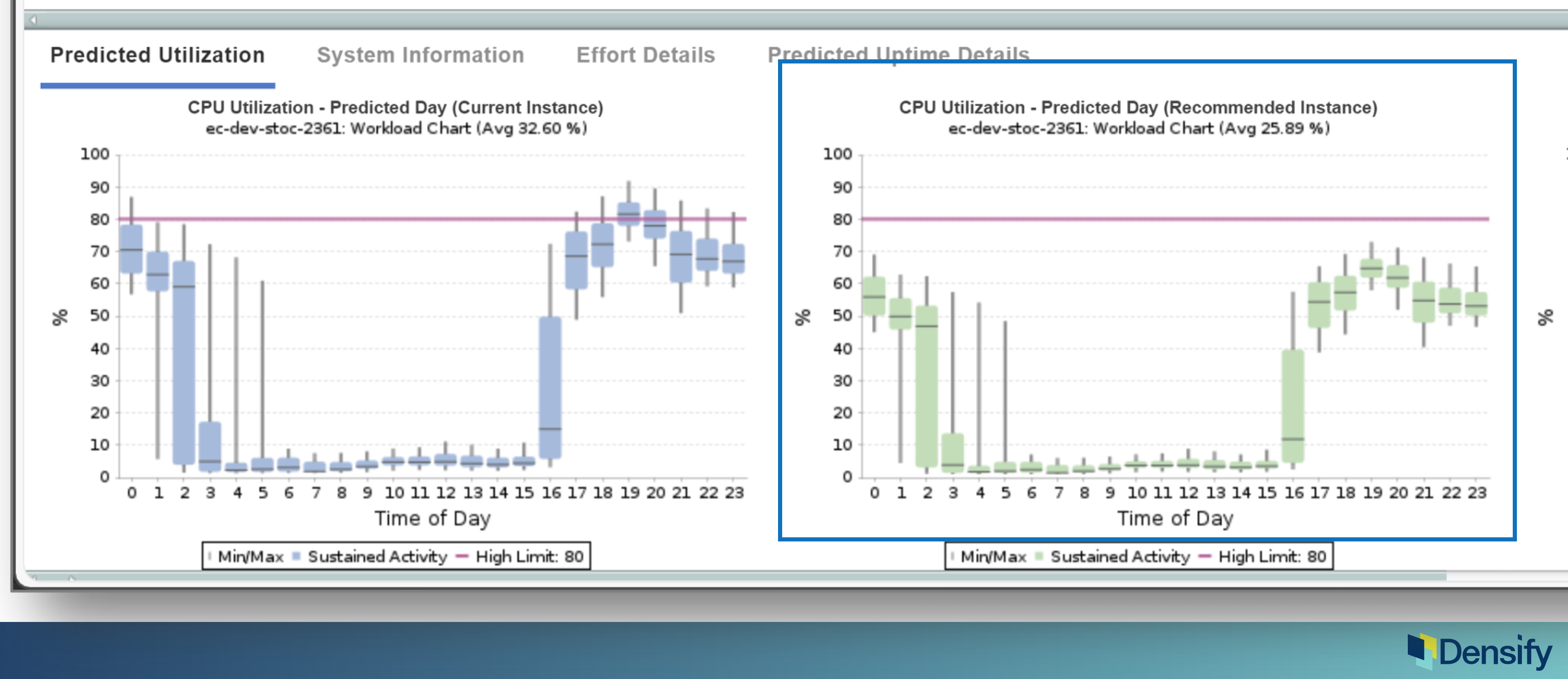
Let’s start with optimization: making it the best. This is drilled down into our Densify UI, down to the level of a cloud instance. There are two cloud instances here and you can see there are a couple of recommendations, in this case one is for 2 extra large onto an R 7Z Extra large. And so this is an interesting case because we’re moving to a smaller but much newer instance. If I look to the right, we’re going to save almost $100/month by doing this – this proves a great financial benefit.
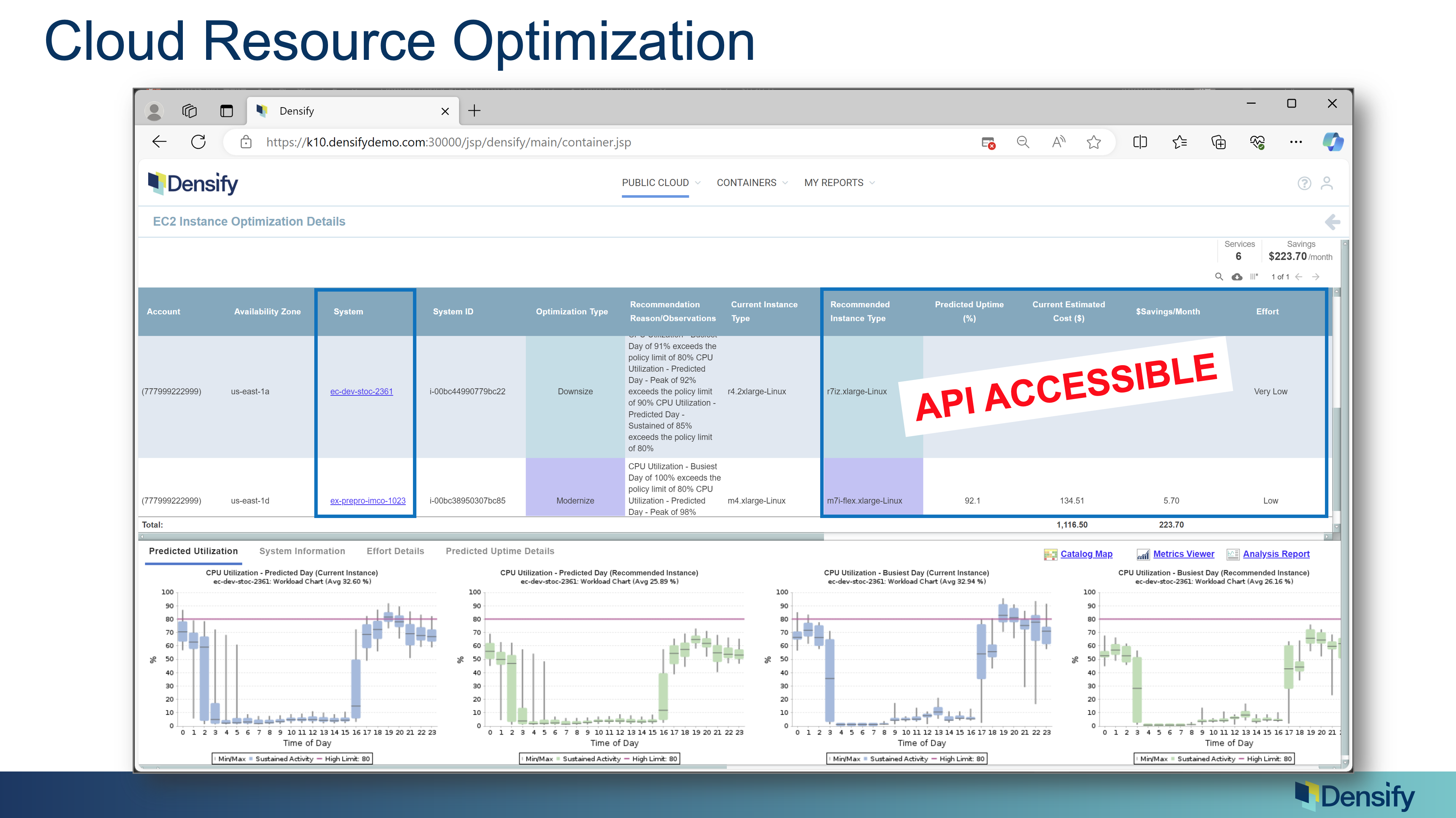
But even more so, if you look at the bottom, the current instance is obviously not big enough to run this workload. This is the 24 hour CPU model and we’re going a bit above the threshold, we might want to get off this one because we’re going to get pressure pretty soon (that’s this blue curve on the left.)
The green curve is the predicted view on that new instance type and it’s going to be lower; in this case not only is this instance cheaper, it’s actually faster = high value and save money and this will actually work better for the app team. When you show an app team, “hey, we’re going on something newer”, it’s like I’m going to give you a new laptop that has much faster CPUs: it has fewer CPUs, but much faster CPUs. And there is proven benefit in this.
8. The evidence: App owner report
All of this is available through APIs, which we also talk about how we integrate into the Accenture processes with this.
There is also what we call an app owner report, which gives the details; the rationale to the app teams of why we’re making specific recommendations – and I can’t emphasize enough why this is very important.
It’s not enough to have the right answer. You have to explain why it’s the right answer. And you have to make sure the application teams understand it and can prioritize it and do it.
For example:
What policy was enforced? Well, if we looked at the last 90 days of data using very conservative policies and all these thresholds and we’re saying:
- This is what you should do
- This is what it’s going to look like along with a detailed rationale
- And this is the proof of potential savings

Putting this report in front of the app teams it’s very logical that there’s no reason why not to do this unless they have some very unusual requirements. It also makes for a great discussion and then greases the wheels for action.
9. Taking recommendations
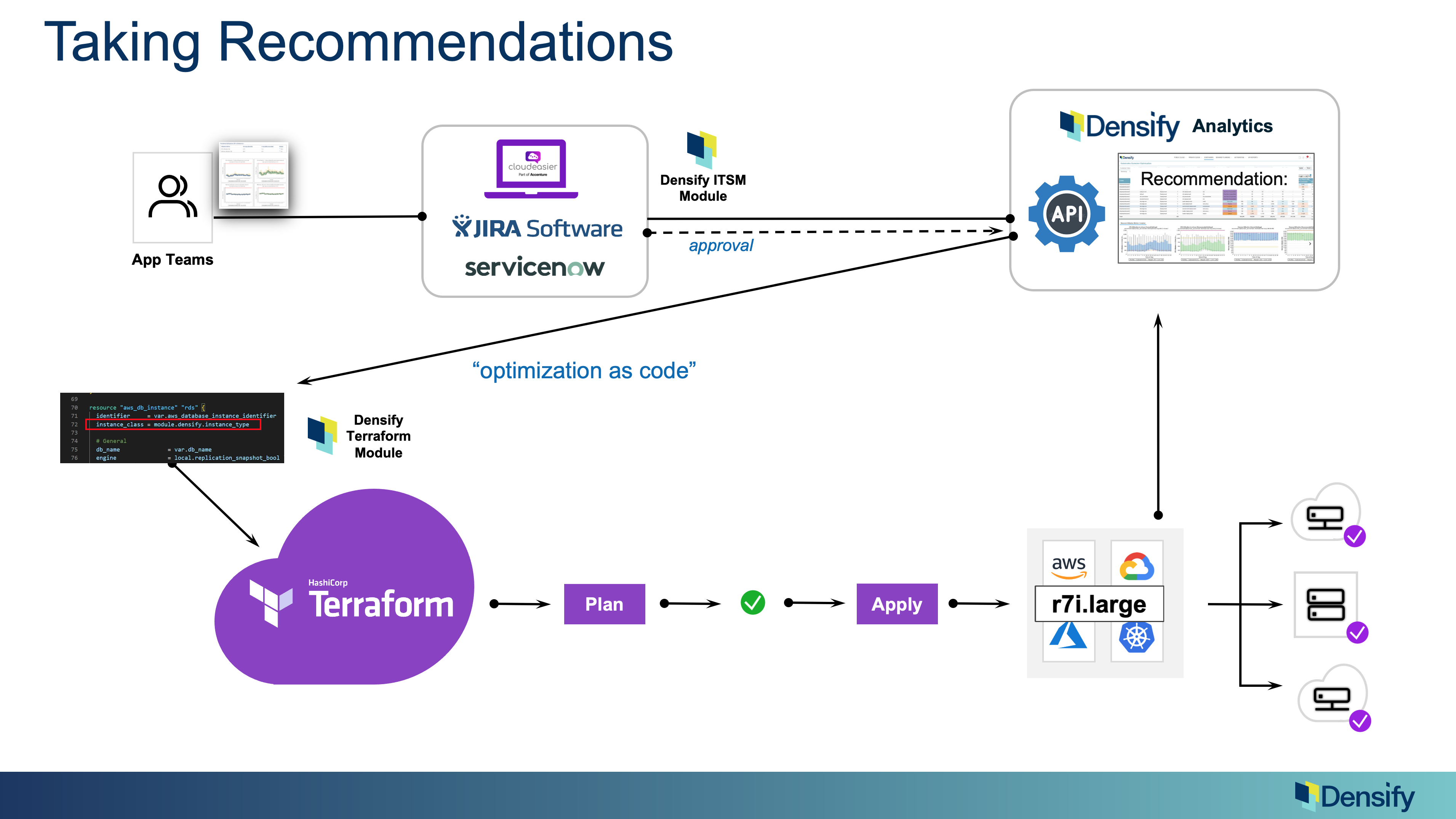
Densify has a lot of different integrations into the ecosystem. We derive the optimal recommendations, then make those available to the systems that will manage and track the changes.
For example, Densify has an ITSM module that can open tickets into a change management process. Another example is an integration with Accenture’s Cloudeasier solution. We also have ways of interacting with infrastructure as code such as Terraform. The point is to make the recommendations easy to take action on within the ways that an organization prefers to act.
How Densify solves the cloud efficiency challenge: Concluding notes
What I have covered is the way Densify enables FinOps by taking seriously the need to credibly present better infrastructure and instance choices to app owners. By focusing on the quality and accuracy of the recommendations and providing detailed proof as to why a recommendation makes sense, we increase the likelihood that an app owner will take action on a change…and as a result, drive down cost. This is balanced by having equal attention and care to finding ways to make recommendations that will also improve performance…a critical element in engaging with application owners. With a balanced approach that illustrates an interest in overall improvement along with cost reduction, the odds of success are greater.
Interested in seeing what Densify can do for your org? Request a customized Cloud & Kubernetes Optimization Demo »