

It’s no secret that Kubernetes is one of the fastest-growing technologies in use today for deploying and operating applications of all types in the cloud. It’s also no secret that Kubernetes’ popularity is a significant contributor to fast-growing cloud bills.
FinOps teams are constantly looking for ways to lower their cloud spend, in cooperation with the DevOps, Engineering and App owner teams that control this infrastructure. A frequent target for this downsizing is the Kubernetes nodes on which the containers run.
Observability tools, free tools from cloud providers, and enterprise bill readers often produce downsize recommendations for the node infrastructure. However, if you consider reducing the size of those nodes without looking more deeply at the root cause of oversizing, you might be doing it wrong. And doing it wrong can have serious consequences on the state and stability of your K8s environment, not to mention destroying the trust from the engineering team(s).
What is Driving the High Cost?
Basic approaches or finance oriented tools typically only see the CPU/memory utilization of the Kubernetes nodes and will commonly identify opportunities to reduce number of nodes or downsize their resources. Here’s a sample result of CPU driven utilization from a Kubernetes cluster of nodes.
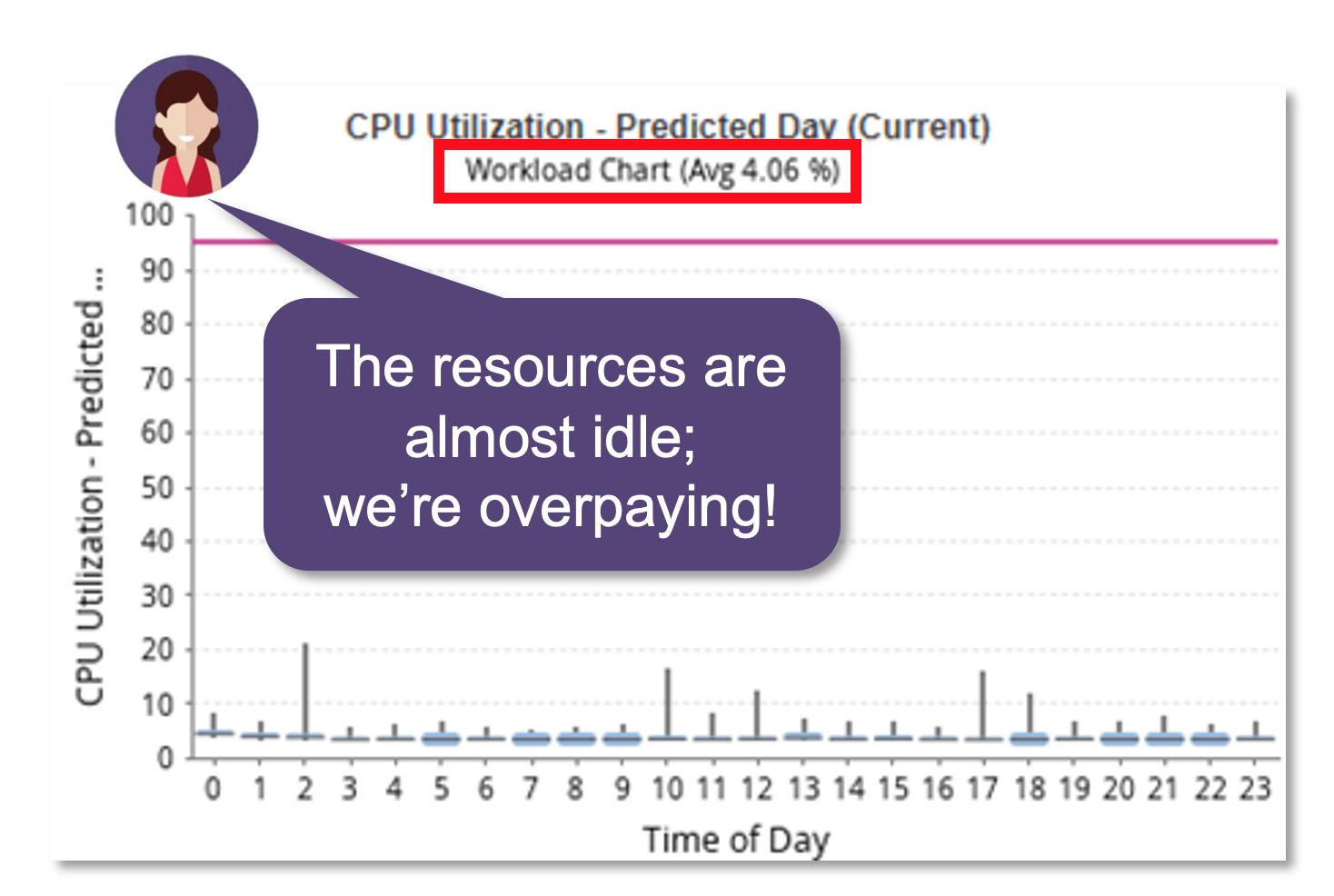
Meanwhile, the Kubernetes scheduler only sees the resource requests that have been applied by the application owners, which indicates no opportunity for downsizing as-is.
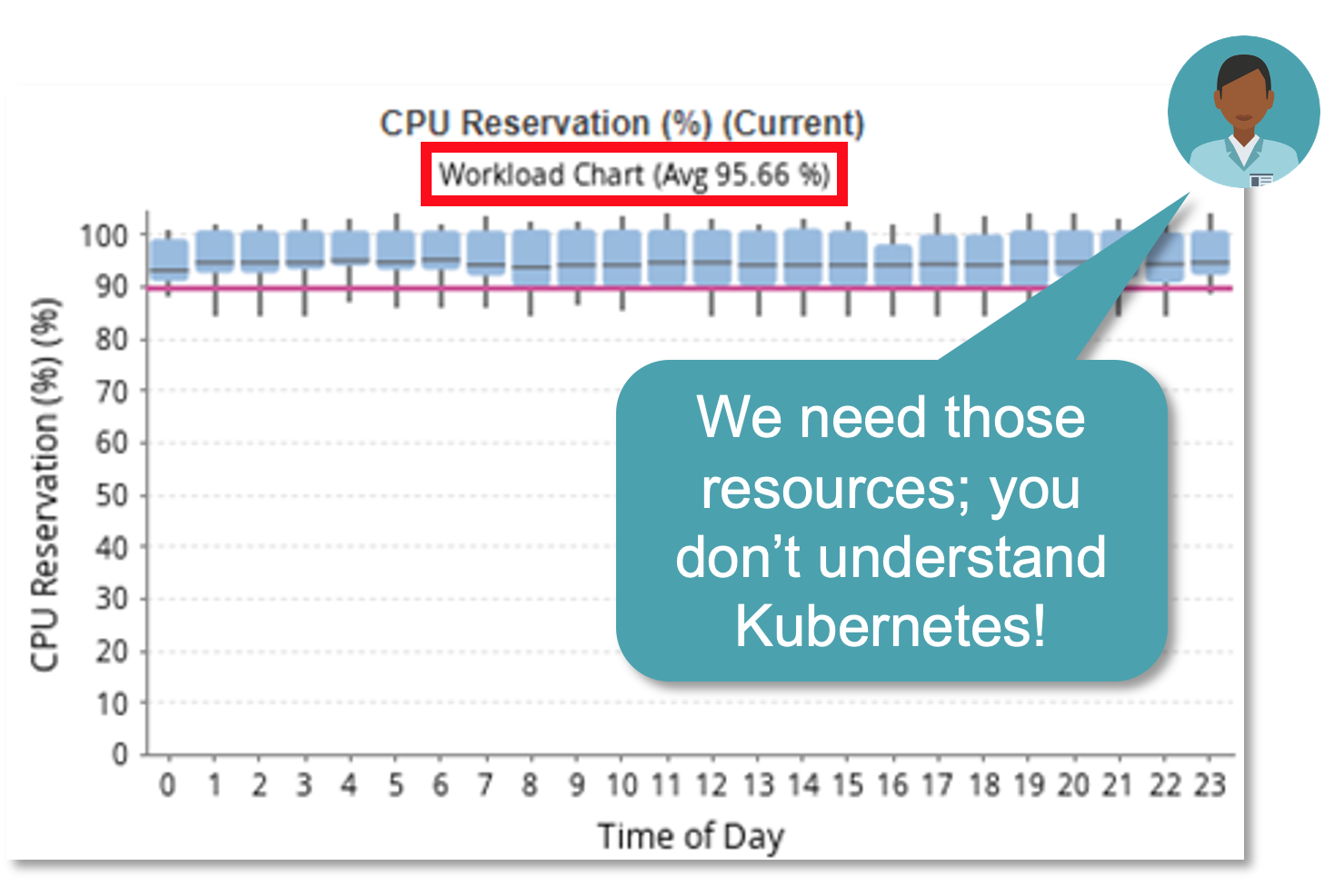
Here’s an actual (sanitized) example from a customer environment of the results when recommendations from their enterprise bill reader were considered to try to drive savings via node right-sizing.
| Current Environment | Recommendation | |
|---|---|---|
| Instance Type | m5.8xlarge | r5a.2xlarge |
| Instance CPU cores | 32 | 8 |
| Instance Memory | 128GB | 64GB |
| Number of Nodes | 14 | 14 |
| Cluster Resources | Cluster Resources | |
| Total CPU Available | 448 | 112 |
| Total Memory Available | 1792 | 896 |
| Estimated Hourly Cost | $0.97/hr | $0.29/hr |
| Monthly Cost | ~$9,777 | ~$2,923 (70% Savings!) |
On the surface, this appears to be a solid cost-savings recommendation. Why wouldn’t one downsize the container node resources to achieve 70% savings (around $6.8k per month, $82k per year)? Unfortunately, the primary constraint in this customer’s environment was CPU requests at the container level, but the financial tool had no visibility of this resource constraint. If this recommendation were to be followed, the result would have been catastrophic for the applications’ performance.
Here’s the actual math showing what their required spend would have been to accommodate the required resources.
| Current Environment | Recommendation | |
|---|---|---|
| Instance Type | m5.8xlarge | r5a.2xlarge |
| Instance CPU cores | 32 | 8 |
| Instance Memory | 128GB | 64GB |
| Number of Nodes REQUIRED | 14 | 55 (to meet primary resource constraint) |
| Cluster Resources | Cluster Resources | |
| Total CPU Available | 448 | 440 (primary constraint) |
| Total Memory Available | 1792 | 3520 (wasted resource) |
| Estimated Hourly Cost | $0.97/hr | $0.29/hr |
| Monthly Cost | ~$9,777 | ~$11,484 (17% Cost Increase!) |
Key Observations:
- In order to serve the required container resources (~440 CPU cores), the K8s cluster would need to scale up to 55 nodes (r5a.2xlarge)
- Memory would then be overprovisioned at the cluster level by almost 2X, an unnecessary mismatch of resources
- Overall monthly costs for this environment would increase by 17%
The Correct Approach:
- Eliminate Risk: Address undersized containers first. There are possibly under provisioned resources in your environment that could impact performance of the container nodes as well.

- Reduce Waste: Fix oversized containers, the ones that are configured with more resources than are necessary, starting with the Top-10 largest containers

- Optimize Nodes: Only when the container resources are addressed and remedied is it recommended to address node sizing and drive lower costs. It’s important to note that node groups should automatically scale down as containers are remedied.




For more information on how Densify continually right-sizes container resources and subsequently makes optimal node instance recommendations, learn more about the Kubernetes Resource Optimizer or watch a 20-min session (demo included) on Optimizing your Kubernetes Nodes.
Interested in seeing what Densify can do for your environment? Get a demo »



