

How to Configure Your Auto Scaling Groups to Maximize Performance & Minimize Costs
Provisioning traditional data centers to support web and mobile apps was once a no-win situation. You could architect the data center to handle peak loads—and pay for unnecessary resources when usage levels fell back to normal. Or, you could support average daily usage—and risk frustrating customers during times of heavy demand.

Cloud resources with auto scaling capabilities change the equation. Solutions like AWS Auto Scaling automatically scale the amount of computational resources allotted to your operation up or down based on application load.
With right sized resources, your applications always have the capacity to handle current traffic demand. And you save money because you pay for only the resources you use. Simply launch instances when you need them and terminate them when you don’t.
Setting Launch Configurations
However, the key challenge for those seeking to implement autoscaling is setting the proper launch configurations for:
- The type and size of EC2 instance
- The size of the group of instances
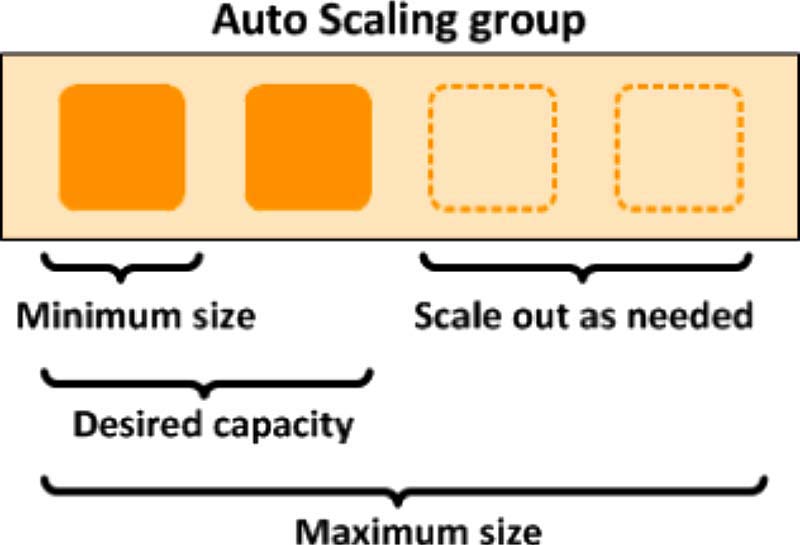
This Auto Scaling group has a minimum size of one instance, a desired capacity of two instances, and a maximum size of four instances. Scaling policies adjust the number of instances within your minimum and maximum based on criteria you specify.
The right parameters will depend on the nature and resource usage patterns of the applications you’re running. Yet, far too many organizations have no visibility into the infrastructure resources their applications need and use.
Enterprise apps in particular often make it difficult to understand which infrastructure resource is being used, let alone the utilization levels of those resources. This makes it impossible to make intelligent decisions as to what node types and sizes, and scaling parameters to use within an Auto Scaling group.
If you set the minimum too high, instances will continue running and costs will continue to rise even if the resources are not needed; And if the levels are set too low, you run the risk of not having enough resources available. In other words, if you don’t set up auto scaling properly, you’re right back where you started. You may as well not have auto scaling at all.
The Role of Machine Learning
The answer is a solution with the intelligence to analyze loads across all auto scaling nodes and groups that can then use this knowledge to optimize the individual node types and sizes to better align the entire scale group with application demands. The solution must also determine the right scaling parameters (min and max group sizes) to precisely support actual demand patterns.
How does such an intelligent solution work?
Such solutions rely on artificial intelligence/machine learning. The machine learning analytics engine starts by determining the right instance type and size. It takes all historical utilization data across the CPU, memory, network I/O, and disk I/O and builds workload profiles that reflect demand on the app, including time-of-day patterns, business cycles, and seasonality.
Next, the engine constantly scans cloud catalogs to stay on top of the latest instance offerings from the major cloud providers, such as AWS, Azure, and Google Cloud. The engine leverages industry benchmarks like spec.org to normalize the cloud supply models to determine what a workload pattern would look like on different instance types and sizes. The normalization process enables apples-to-apples comparison across different instances types and sizes, even across cloud providers.
Finally, the engine employs deep, multidimensional permutation analysis to find the best match between the demand and supply.
This process might determine that an app that uses a lot of memory but leaves a lot of CPU whitespace is memory-intensive and recommend moving from a general-purpose m5.large instance to a memory-optimized r5.medium instance. This move would save 30% of the cost while maximizing app performance. An app using lots of I/O could be moved from a general-purpose instance m5.large to an I/O-optimized i3.medium instance. A bursty app might be moved to a burstable t3.medium instance.
Once the machine learning optimizes the EC2 instance type (e.g. the node type) and size, it’s time to set the group parameters to scale in or out to meet actual demands. The machine learning engine will again look at utilization metrics to determine the best MIN and MAX group size. The engine might find that one auto scaling group should have a minimum of 4 nodes and a maximum of 8 nodes—while it is currently configured for a MIN of 2 and a MAX of 4. In this case, the engine will recommend upscaling to meet the app requirements.
Using machine learning to set the right parameters for AWS Auto Scaling lets you squeeze the greatest value out of your cloud resources. You’ll have the right capacity to maintain peak app performance at the lowest possible cost.
See how your applications can intelligently leverage Auto Scaling groups to scale better:
Request a Demo of Densify Auto Scaling Management


