Capacity Operations
Ensure Continuous, Optimized Resource Delivery for Cloud & Containers
Capacity Operations Bridges the Gap between FinOps & DevOps
Capacity operations is the science and supporting processes of ensuring that applications have the necessary infrastructure to meet their requirements, without having too much. This emerging discipline continuously optimizes compute resources in cloud and container environments via recommendations and directives that are generated from deep analytics. It fills a management gap that has developed between established DevOps and FinOps processes—where analysis of the true resource requirements of applications isn’t performed by either practice—causing inflated bills and unnecessary operational risk.

Capacity operations differs from legacy capacity management in that the aim is less about planning, and instead focuses on continuous alignment of application needs with infrastructure resources for elastic “as-a-service” environments.
Capacity Operations: The Whitepaper
Dive deep into how capacity operations delivers continuous compute optimization for cloud and container environments.
Frequently Asked Questions about Capacity Operations
- Why is capacity operations critical to my business?
- Many organizations have focused cloud optimization initiatives on optimizing their purchasing and properly quantifying and allocate costs—the central focus of FinOps. In doing so, many have lost focus on the actual resources being used—traditionally the focus of capacity management—leaving resource specification to application developers and creating a gap in the capacity management process. This is further amplified by the adoption of containerized infrastructure and Kubernetes, where the specification of resources is much more granular, and getting it wrong at the micro-level has a huge impact on efficiency and risk in aggregate—visible to the business as rising cloud costs and subpar service quality.

The rise of infrastructure complexity and the resource management gap capacity operations exists to fill this gap, providing a discipline to maximize the efficiency, availability, and speed-of-management of cloud and container environments by optimizing the actual resources being used, not just how they are being purchased, thus returning organizations full circle to a more disciplined approach to capacity.
- How does Capacity Operations maximize app availability and increase ease of service delivery?
- Many organizations have significant untapped optimization potential, and even going after just the “low hanging fruit” can justify capacity operations many times over. These organizations have typically adopted technology that allows them to make sense of the cloud bills, and even achieved a level of cost savings through the use of Reserved Instances, Savings Plans, and Committed Use Discounts. But, they have hit a wall when it comes to optimizing the actual resources being used, and they quickly realize that managing the bill isn’t the same as managing capacity. Adding to this, the deployment of containers typically creates a whole new level of stress at a scale that is impossible to optimize manually.

Capacity operations exists at the nexus of FinOps and DevOps concerns, focusing on optimizing what resources your workloads actually consume. Capacity operations sets a high bar for Development and Ops teams, but ultimately saves them time, eliminates concerns, speeds delivery, and creates meaningful business benefits:
- Increasedoperational focus and precision of optimization recommendations enables teams to take action. Robust policies ensure that capacity optimization recommendations align with application and vendor requirements and can be operationalized efficiently.
- The recommendations that are generated from capacity operations analysis integrate seamlessly with reporting, business intelligence, and change management systems, and even DevOps tooling and pipelines, where automation can occur. Optimization directives take machine-readable and human-readable form, enabling transparency as well as automation.
- Application owners and managers benefit from increased transparency into their services through reporting on the before and after of resource optimizations and the total alleviation of any resource selection tasks, enabling them to look forward to releasing new functionality instead of back to tune already-deployed components. As load increases after the initial app deployment, components are automatically optimized and benefit from historical optimizations.
- Resource optimization tasks are automated over time and are congruent with change management requirements, providing for transparency, change control and ITSM integration, and full automation of the change upon approval. With sufficient trust in the analytics (consistent with the precision requirement) some organizations have negotiated with app teams to remove the approval requirement, which greatly streamlines the automation process.
- Who is commonly involved in capacity operations processes?
- Capacity operations plugs the financial and risk management holes left by the often myopic focus on cloud financials and requires the participation of some of the same experts responsible for DevOps. Ownership of the process and required tooling will vary depending on the size and maturity of automated processes within your organization, but important stakeholders typically include:
- Architects: Those responsible for designing a cohesive centralized platform and tooling stack to deliver services to the organization
- Cloud Engineers: Those responsible for building DevOps and CI/CD workflows and automated provisioning
- Container Service Owners: Infrastructure managers who are responsible for operating and delivering containers as a service (CaaS) with an specific SLA, at a cost-efficient rate
- Capacity Managers: In mature organizations operating at greater scale, given their experience and focus, virtualization Capacity Managers can take on the responsibility of ensuring that the practices and benefits of capacity operations are best leveraged by their organization
- How does capacity operations work in the cloud?
- Cloud infrastructure enables you to deploy production resources in seconds through API calls or infrastructure as code solutions in an elastic micropurchasing model that eliminates the need for many traditional capacity management activities. But, this doesn’t mean capacity can be ignored.
Cloud demands a completely different set of resource optimization activities with new fundamental assumptions. For example, even taking inventory is now very different than in on-prem environments, more closely resembling a “stock chart” of ups and downs than a static count. Even traditional capacity operations like rightsizing VMs now requires a different approach that is subject to decentralized decision-making. The micropurchasing model enables agility, but also forces resourcing decisions into the hands of engineers and developers who often do not have sufficient information to make the right choice. Suboptimal resource micropurchases, in aggregate, can amount to significant costs and tremendous inefficiencies.
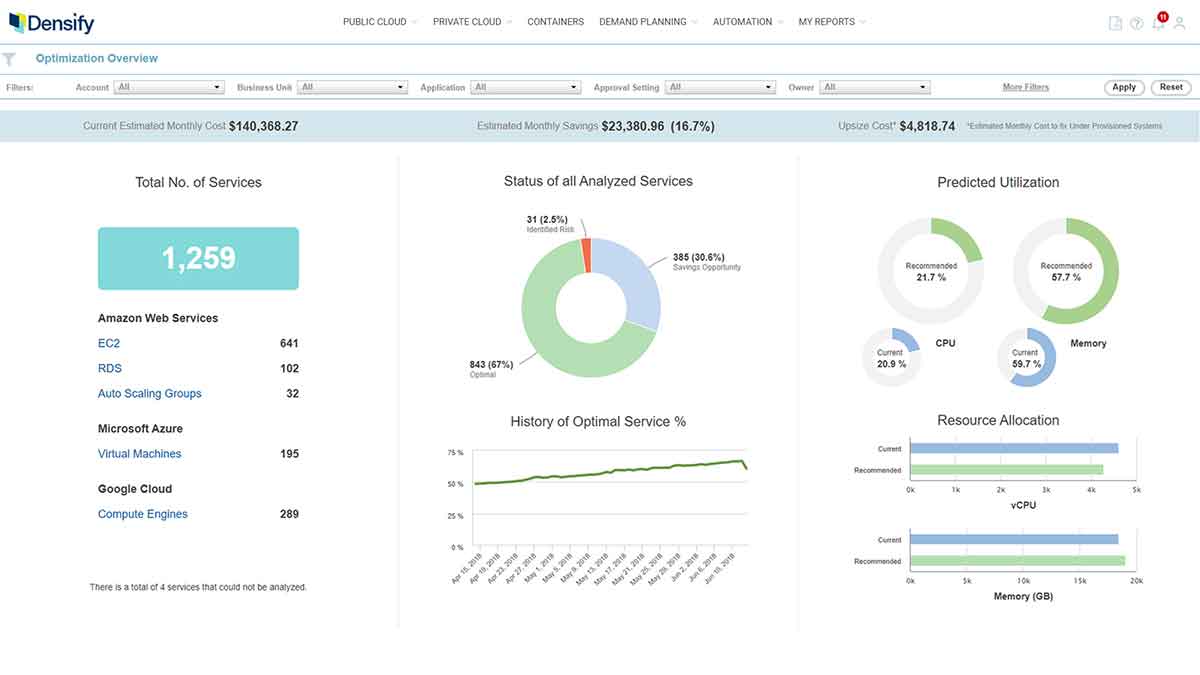
Cloud capacity optimization overview dashboard There are a set of fundamental capacity optimization practices that must be performed in order to make sure that the right cloud resources are deployed at any point in time, including:
- Instance sizing (upsize, downsize) – Rather than optimizing resources directly on a VM, resources are now specified in IaC automation pipeline manifests, and any optimization must be embedded in these manifests or the running instances will revert back to what the code says
- Instance termination
- Instance family optimization (e.g. memory optimized, CPU optimized, burstable) – Keeping current with the minutiae of cloud services and new family offerings is difficult for even the most agile businesses and engineers
- Scaling group node optimization (node type and size)
- Scaling group scaling parameter optimization (elasticity) – Focused on configuring the dynamic response to load in an optimal manner, something that is not possible in legacy environments, requires intense scrutiny and expertise to complete manually, can balloon costs when done improperly
- Database as a service optimization
Capacity operations provides a formalized practice to ensure that these operations are performed and happen in a precise and continuous manner. Many organizations have focused on the cloud bill and have achieved a high level of maturity with respect to how resources are purchased. Capacity operations adds to this by also optimizing what resources are being purchased.
- How does capacity operations work in container environments?
- Containers are even more dynamic and granular with orders of magnitude greater entities that must be optimized. Containers can be combined into pods, replica sets, deployments, and other structures, which can be launched with common manifests—and all of these structures can be governed by various quotas to control resource usage. Containers have undeniable benefits when it comes to the flexibility and agility they provide, but providing suboptimal resource specifications creates tremendous inefficiencies at scale, leaving resources stranded and node utilization very low.
Containers do not overcommit resources in the same way VMs do, meaning that cluster administrators cannot simply tune environments to get higher density. Resources assigned to containers are actual resources, meaning they cannot be given out to multiple consumers at the same time. This removes a key weapon in the battle against inefficiency, and any resource overspecification translates directly into the need for more infrastructure, directly impacting cost.
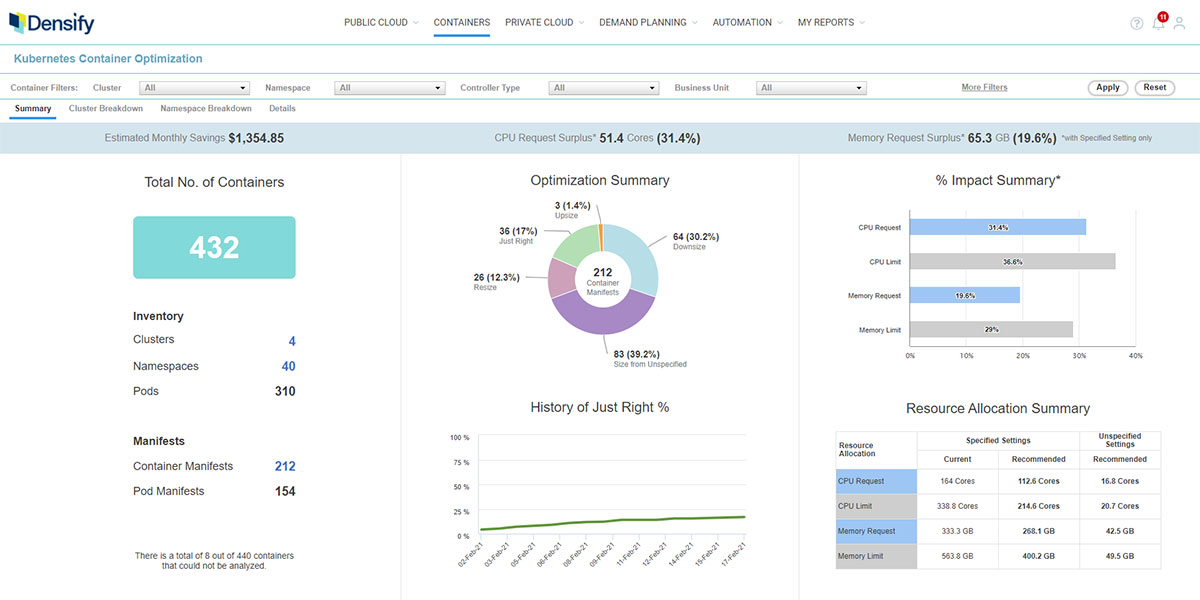
Kubernetes capacity optimization overview dashboard At scale, tiny inefficiencies with each container snowball, and even containers or microservices that run for a very short length of time have a meaningful impact. To combat this, capacity operations addresses the following:
- CPU request optimization – The container scheduler must ensure that sufficient CPU resources are supplied to meet the request values of all containers on a node. If this value is too high (which is common) the scheduler will spread the containers across more nodes than necessary, and utilization will be low.
- CPU limit optimization – Setting this maximum too low will throttle the performance of a container
- Memory request optimization – Allocating too much memory to a container will strand resources, and workload density will be low. Unlike CPU, if this value is too low, the scheduler may place too many containers on a node, and when their aggregate memory utilization goes above the request allocation, the scheduler will actually kill containers to free up resources. This Out of Memory Killer (OOM Killer) is very dangerous, and can be avoided with proper resource optimization.
- Memory limit optimization – When this maximum memory value is too low, containers may be terminated if their utilization exceeds this limit
- Node resource optimization – When containers run in the cloud, nodes are cloud instances, typically running in scaling groups, and optimization procedures are similar to cloud instance optimization. Because the container and node configurations affect each other, the two forms of optimization must be done simultaneously to ensure that the nodes are constantly aligned with the needs of the containers. For example, as container CPU requests are reduced, it might be necessary transition to memory-optimized nodes to maintain efficiency. In on-prem environments, the nodes may be VMs (optimized via sizing and placement) or bare metal, requiring long-term purchase planning consistent with an on-prem capacity management practice
- How is capacity operations distinct from FinOps?
- FinOps—cloud financial operations—is directed at providing transparency and insight to the costs associated with infrastructure spend. This includes a broad array of operations related to managing the financial side of cloud consumption, from chargeback to taxation to optimizing discounts. Although optimizing capacity has a significant impact on costs, many FinOps teams do not have the bandwidth or specialization to optimize the actual resource consumption, ensure the optimal selection of infrastructure, configure optimal application scaling parameters, etc..
While cost efficiency is a benefit of both FinOps and capacity operations, the two disciplines approach this goal from very different directions, and capacity operations is specifically designed to address the range of resource optimization strategies that are possible in cloud and container infrastructure, including spending more if necessary. Capacity operations enables developers with an API for optimization so they can include proper sizing as part of their automation pipelines.
- How is capacity operations distinct from DevOps?
- DevOps is generally focused on delivering applications and services at high velocity, and provides a revolutionary paradigm for dynamic, continuous application development, delivery, and operation. But, the optimization of resources being used by these applications is typically not within the scope of the DevOps process, and continuous deployment rarely includes continuous optimization. This is because the resources required by the application components are often defined “upstream” by the developers or engineers working with the toolchain (via Terraform, Helm, etc.), and these people often don’t have access to insights or analytics that can help them make this decision.
capacity operations provides this transparency, giving precise optimization recommendations that can be used by DevOps teams to guide their decisions, and can even be embedded in their templates to provide optimization automatically.
- How is capacity operations different from traditional capacity management?
- There are several main differences:
- Cloud infrastructure is completely elastic, with a theoretically endless supply of resources, and companies can pay for what is needed, when it is needed. This flexibility often breaks traditional capacity management approaches, which are not designed to continuously control capacity and identify inefficiencies in real time (thus capacity “operations” rather than “management”).
- Any applications are now designed to be stateless whereby processes are run when required and then are killed, and can even exist for very short periods of time. Many legacy approaches cannot account for this fluidity, where the resources consumed by a workload might be measured in CPU hours instead of VMs, and looks more like the area under a curve than something that can be counted. Traditional capacity management approaches are not equipped to optimize things that they cannot even measure.
- Capacity management focused on work that must be done before deployment, as manually adjusting resources after deployment is both hard and expensive.
- Capacity operations leverages declarative infrastructure sizing that is “plugged in” to the deployment pipeline on-premises, in the public cloud, and in kubernetes. Sizing is tied to business KPIs for transaction load, while costs are tied to app and service-level costs plus shared costs. Capacity operations includes the predictive consideration of many possible business cycles, for example calendar/seasonal and business events.
- What are the key components of a capacity operations solution?
- A Capacity operations system will include:
- A data collection framework
- An analytics engine
- An open database
- APIs
- A reporting engine
- An end-user interface
When delivered in a SaaS model, this enables integration into virtually any ecosystem, leveraging existing data sources, management systems and automation frameworks in order to provide capacity optimization. A capacity operations system should be minimally intrusive, and should only require read-only credentials to get up and running.
In order to construct a model of a cloud or container environment, a capacity operations system should be capable of acquiring resource-level data from cloud APIs (e.g. AWS CloudWatch or Azure Resource Manager), billing data (AWS CUR, Azure cost information), container data (e.g. Prometheus), and any associated tagging or metadata. This enables the analytics to build a complete model of the supply and demand in the target environments and generate precise, actionable answers.
Core to the analysis process is deciphering usage patterns and relating them to resource requirements, which requires machine learning. By learning the patterns of activity and then performing deep analysis of the workload patterns against cloud catalogs and container resource models, precise recommendations can be generated.
- What kinds of recommendations are produced?
- Capacity operations is designed to align resources with the real-time demands of applications and business services according to their SLAs. This includes matching an application’s demand profile (i.e. CPU-intensive, nighttime batch processing, etc.) with the available supply and optimal scaling characteristics (i.e. scaling min/max, requests/limits, etc.). To do this, capacity operations generates numerous types of recommendations, including:
- Cloud instance sizing
- Instance family optimization
- Database optimization
- Scaling group optimization
- Container optimization
- Container quota optimization
- Container cluster capacity optimization
- Termination
All of this is driven by detailed policies that reflect the requirements, desired strategy, criticality, etc. for a given set of workloads.
- What specific outputs does a capacity operations system generate?
- A capacity operations system produces two types of output:
- Human-readable output that enables socialization of any recommendations, and helps app owners and other stakeholders understand the impact of any recommendation, both from a technical and cost perspective. This is often attached to change tickets, providing a transparent, controlled method to garner approvals.
- Machine-readable output designed to be used directly by automation frameworks, and leveraged within Terraform, Cloudformation, Helm, Ansible, and other automation technologies in order to enable automated implementation of optimization recommendations.
Both of these forms of output are API accessible, and both can be used together, enabling approval-based automation workflows.
- Does capacity operations require automation to be effective?
- Although automation is typically a long-term goal, automation is not initially required to achieve significant business benefit. Many organizations start by simply ranking the efficiency of different areas of their organization, such as lines of business or app teams, providing an incentive to make improvements based on the capacity operations analytics. Combining this with detailed impact analysis reports and intelligent prioritization, tangible benefits can be achieved without automation. When policies have been tuned and a high level of confidence in the capacity operations technology has been achieved, then the next logical step is to enable automation, accelerating the business benefit and reducing the involvement of stakeholders.
Manual capacity optimization will not achieve the full benefits intended by capacity operations. You must eventually automate the decisioning and adjustment of component sizes at scale to overcome barriers presented by suboptimal resource allocation at scale.