OpenShift Architecture
Chapter 1- Introduction: OpenShift Tutorial
- Chapter 1: OpenShift Architecture
- Chapter 2: OpenShift Route
- Chapter 3: Openshift Alternatives
- Chapter 4: OpenShift Service Mesh
- Chapter 5: Understanding OpenShift Container Storage
- Chapter 6: Using Azure OpenShift
- Chapter 7: Rancher vs. Openshift: The Guide
- Chapter 8: OpenShift Serverless: Guide & Tutorial
- Chapter 9: Anti-Affinity OpenShift: Tutorial & Instructions
- Chapter 10: OpenShift Operators: Tutorial & Instructions
OpenShift Container Platform (OCP) is Red Hat’s enterprise-level software and support integrated into a Kubernetes cluster. Red Hat’s OpenShift Container Platform lets IT teams leverage enterprise-grade software with support from an industry-leading vendor.
Because OCP includes many components, it can be difficult for the uninitiated to understand OpenShift architecture. However, it gets easier when you think of OpenShift as a specific flavor of Kubernetes, like how Red Hat is a flavor of Linux. In fact, because OpenShift integrates with Kubernetes, many of the concepts and components found in a Kubernetes cluster directly apply to OpenShift architecture.
In this article, we’ll provide a high-level OCP overview, review core concepts and terms, and highlight OCP architectural components.
OpenShift architecture key terms
To understand OpenShift architecture, you should be familiar with these key terms:
- Machine: A physical or virtual machine. A machine is unconfigured and unmanaged with regards to the cluster.
- Node: A node is a virtual or physical machine configured and managed by a cluster.
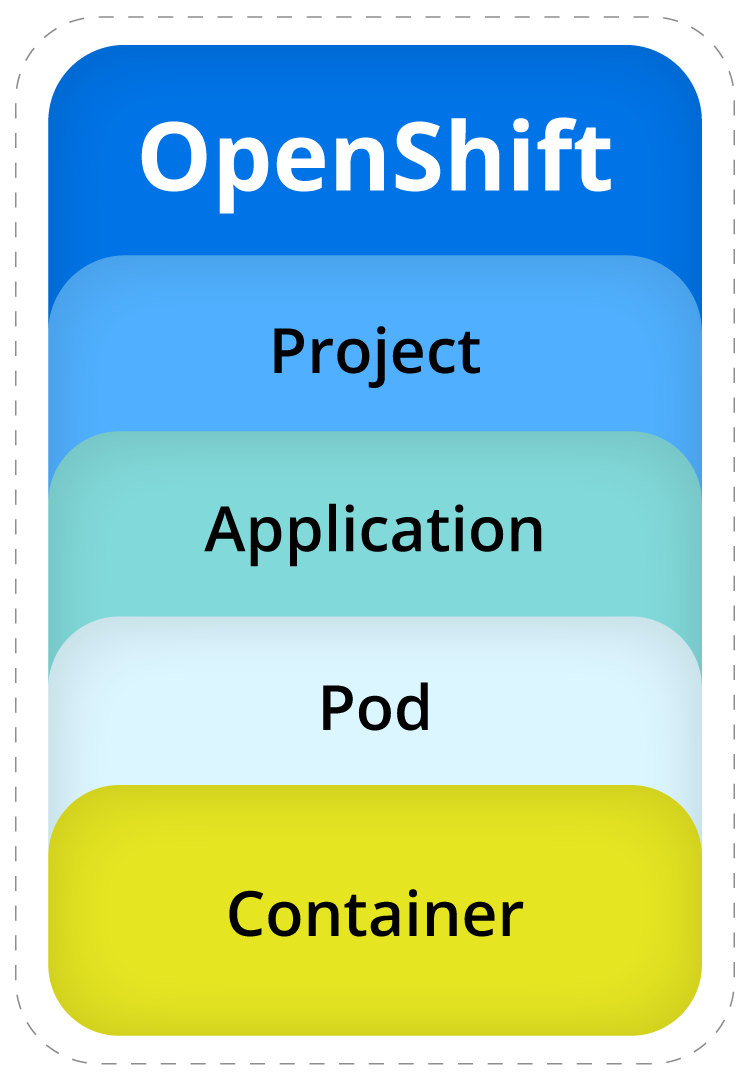
- Project (OpenShift)/Namespace (Kubernetes): An OpenShift project represents resource isolation from other projects on the cluster. Think about it as a folder on your computer. It provides scope for naming and access control. In Kubernetes these are called Namespaces.
- Pod (Kubernetes): A Kubernetes pod represents an individual process or job within a cluster. A pod groups and manages one or more containers as a single object.
- Container: A container is an application packaged with all the required resources to run in an isolated environment.
OpenShift Architecture Overview
OpenShift is a highly resilient and scalable container orchestration platform. It addresses many common infrastructure challenges associated with moving workloads to the cloud.
Configuration of all the moving parts is abstracted away through declarative configuration files written in YAML. In other words, these YAML files are instructions for how OCP configures infrastructure components like networking and pods (containers) in a cluster.
Below, we’ll review the key infrastructure components of OpenShift Architecture: Cluster Nodes, Red Hat CoreOS, Cluster Operators, and Cluster Networking.
Cluster Nodes
A cluster is made up of two types of nodes:
- Control plane nodes: Handle the cluster API, role-based authentication (RBAC), and the scheduling of pods across the worker nodes
- Worker nodes: Manage the creation and overall lifecycle of the pods.
A cluster must have at least three nodes in the control plane. Etcd keeps the cluster status in sync across all the nodes. Worker nodes make up the rest of the cluster.
Note it is possible to define custom node roles. A common custom node role is an infrastructure node that runs containerized versions of networking components.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 30-day TrialRed Hat CoreOS
Each node in an OpenShift cluster runs Red Hat CoreOS (RHCOS) as the base operating system. RHCOS is based on the Red Hat Enterprise Linux (RHEL) operating system and optimized for running containers. RHCOS and RHEL use the same kernel and receive the same updates and bug fixes.
The MachineConfig Operator (MCO) manages node updates. Node updates are delivered via container images that are written to disk. When a node reboots, it boots into the new updated image.
Cluster Operators
Operators are an essential concept in Red Hat OpenShift. Operators run a continuous control loop to check the current status of an application against the desired state. If the current state and the desired state are not in sync, the operator works to bring the current state to the desired state.
For example, if the desired state is to have three copies of a pod running, but there are only two, the operator will bring up a third pod.
Operators have two classifications:
- Platform operators: Platform operators are managed by the Cluster Version Operator (CVO), which handles cluster-wide operations. Monitoring, logging, and node provisioning are examples of cluster-wide operations.
- Add-on operators: Add-on operators are managed by the Operator Lifecycle Management (OLM) operator. These are any other operators required to meet business needs. Common examples include database operators such as MariaDB or PostgreSQL.
Cluster Networking
Cluster networking is handled through software-defined networking (SDN) instead of traditional physical routers, load-balancers, and firewalls. For an OpenShift cluster, a set of network operators in the cluster handle things like routing traffic, load-balancing, and network policies.
Each pod in a cluster is assigned an internal IP address so pods within the same node can talk to each other.
If communication is needed across the cluster, OpenShift has a DNS service and ingress and route API resources that manage traffic flow.
OpenShift Networking Resources
| OpenShift Resource | What It Does |
|---|---|
| DNS Service/Operator | Runs CoreDNS to provide name resolution and service discovery within the cluster |
| Ingres API | Responsible for managing external access to the cluster |
| Route API | Provides a public URL to your application |
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 30-day TrialOpenShift Cluster Node Details
With an understanding of the fundamentals of OpenShift architecture out of the way, the following sections will take a closer look at OpenShift control plane and worker plane nodes.
OpenShift control nodes
The control plane nodes are the nodes that manage the deployment of pods onto the worker nodes. A production environment requires at least three control plane nodes.
A series of Kubernetes and OpenShift services runs on each control plane node.
Kubernetes services
- kubeapi-server: The kubeapi-server is the interface for validating and configuring API objects such as pods, services, etc.
- etcd: Etcd is a key-value store that maintains the status of the cluster across the control plane. Cluster objects watch, etcd, to bring themselves into the desired state.
- kube-controller-manager: EA controller in Kubernetes is a continuously running loop to check the desired state of a component with the actual state and keeps the two in sync.
- kube-scheduler: The scheduler assigns pods to nodes based on resources available and node designation.
OpenShift services
- OpenShift API server: Managed by the OpenShift API Operator, this service provides the API interface for OpenShift components such as routes and templates.
- OpenShift controller manager: Managed by the OpenShift Controller Manager Operator, this service monitors etcd for state changes and tries to bring desired and current state in sync.
- OpenShift OAuth API server: Managed by the Cluster Authentication Operator, this service provides OAuth tokens for users and groups.
- OpenShift OAuth Server: Users make requests to this service to authenticate themselves.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 30-day Trialsystemd services
In addition to these services and pods, the following systemd services run on control nodes.
- CRI-O: The container engine used to manage running containers in OpenShift / Kubernetes.
- kubelet: The service that accepts requests for managing containers.
OpenShift worker nodes
Worker nodes make up the rest of the nodes in a cluster. These are the nodes where the control plane schedules pods. Each worker node will let the control nodes know how much capacity they have so the control node can determine where to schedule nodes.
Like control nodes, worker nodes run the CRI-O and kubelet services.
Resource management for OpenShift Projects
In OpenShift, a project represents a Kubernetes namespace. The term namespace describes a collection of pods in a cluster. Pods represent workloads on a cluster and contain one or more containers. Pods run on both control nodes and worker nodes.
By default, a pod does not have resource limits and can consume memory and CPU without restriction. It is up to the cluster administrator to monitor and adjust resource usage.
Quotas and limit ranges are a way to limit the amount of CPU and RAM a particular project can consume and improve cluster resource management. Depending on the cluster’s size, understanding historical resource usage and deciding how best to utilize resources can be a significant undertaking that requires specialized tooling. Densify is one such tool/platform to help with resource utilization. Integrating tooling dedicated to analyzing and learning about your applications specific usage can help right-size your resources. This could mean highlighting oversized instances not needing as much usage as allocated or identifying under powered instances where resources could be added for potentially better performance.
Spend less time optimizing Kubernetes Resources. Rely on AI-powered Kubex - an automated Kubernetes optimization platform
Free 30-day TrialConclusion
To recap some of the key takeaways from this article:
- Machines are unconfigured cluster nodes.
- Each OpenShift node runs Red Hat CoreOS (RHCOS)
- The control plane schedules pods on worker nodes
- Worker nodes are where the real work occurs
- OpenShift operators help align the current state of a cluster with the desired state
- OpenShift uses software-defined networking (SDN) enabled by network operators
Red Hat’s OpenShift is an enterprise-grade solution, and there is still plenty more to learn about this powerful container orchestration platform. Future articles in this series will dig deeper into the core components of your OpenShift cluster.
FAQs
What is OpenShift architecture?
OpenShift architecture is Red Hat’s enterprise-grade container orchestration framework built on Kubernetes. It includes control plane nodes, worker nodes, Red Hat CoreOS, operators, and software-defined networking to deliver scalability and resilience.
How do control plane nodes work in OpenShift architecture?
Control plane nodes handle the API, RBAC authentication, scheduling pods, and maintaining cluster state with etcd. A production OpenShift architecture typically requires at least three control plane nodes for high availability.
What role does Red Hat CoreOS play in OpenShift architecture?
Every node in OpenShift architecture runs Red Hat CoreOS (RHCOS), a container-optimized OS based on RHEL. It’s managed by the MachineConfig Operator (MCO), which delivers updates through container images.
Why are operators critical in OpenShift architecture?
Operators continuously monitor the cluster state and reconcile it with the desired state. Platform operators handle core services like logging and monitoring, while add-on operators manage custom workloads like databases.
How is networking managed in OpenShift architecture?
Networking relies on software-defined networking (SDN). OpenShift assigns pods internal IPs, manages DNS with CoreDNS, and provides Ingress and Route APIs to handle external traffic and expose applications securely.
Try us
Experience automated K8s, GPU & AI workload resource optimization in action.
Try us
Experience automated K8s, GPU & AI workload resource optimization in action.



