
Organizations are moving application workloads to public cloud infrastructure as a service (IaaS) in droves. After all, it’s a cost-effective way to get things done, right? Not necessarily. In reality, many organizations are overspending and overprovisioning their cloud instances is a key reason why. Analysts predict that by 2020, 80% of organizations will overshoot their cloud IaaS budgets due to a lack of effective cost optimization.
In this five-part series, we’ll examine some of the common mistakes organizations make when building and managing cloud services, and discuss practical tips for optimizing cloud provisioning to achieve the right balance of cost and performance.

One of the main reasons organizations spend more than they should is that they don’t have a detailed understanding of application workload patterns. The exact nature of a workload has a direct impact on the cost of that workload in the cloud. For example, an application that is a batch processing job will have periodic high utilization, but use little or no resources the rest of the time (see figure below). This would be ideal for the cloud because the pattern is simple and unchanging. You could turn the instance off when it is not active and pay for CPU cycles only during the hours when the application is running.
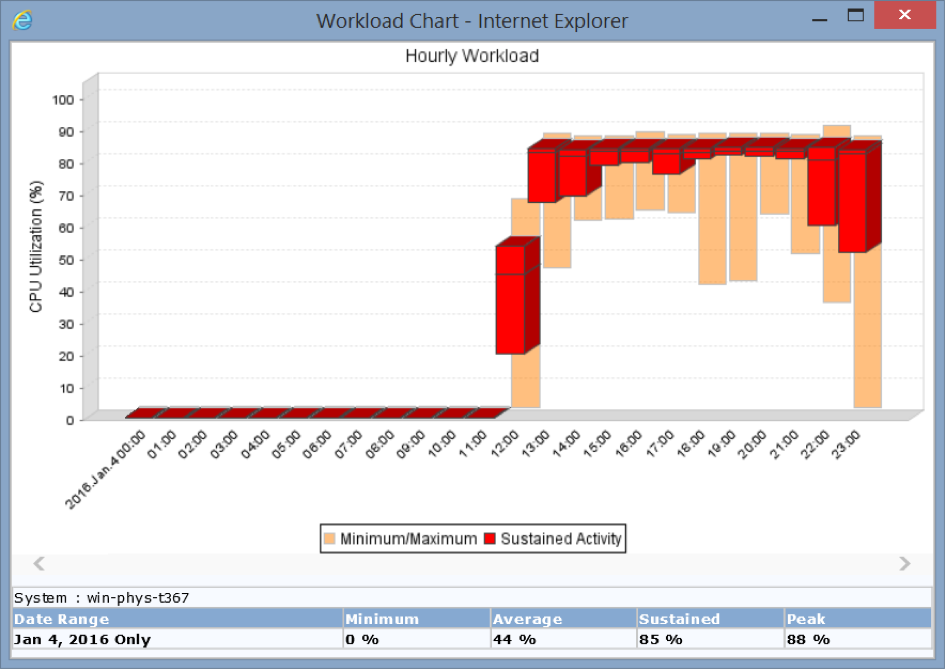
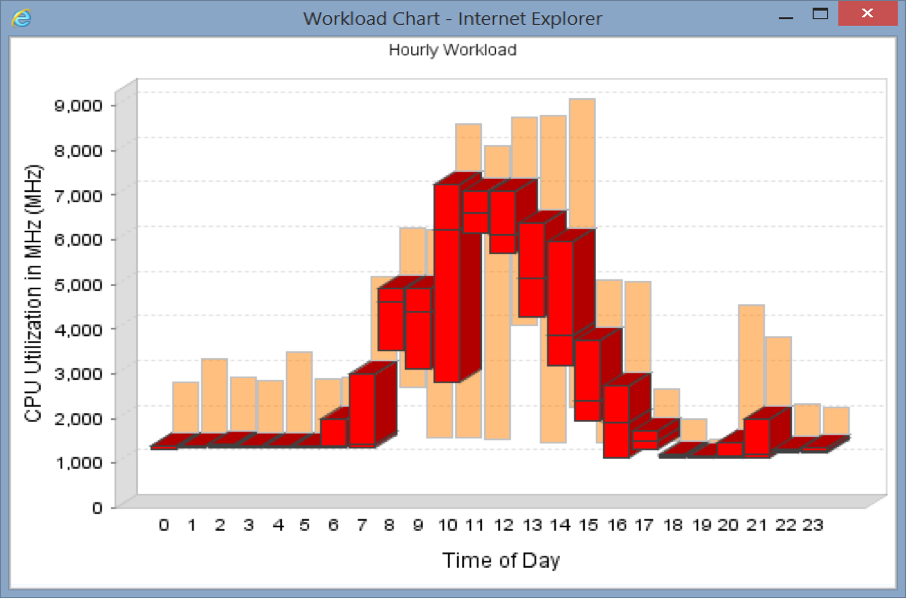
When you contrast this with a transactional application, such as a billing system that is constantly busy but has peaks and valleys throughout the day (see figure below), the economics of running the app in the cloud are quite different. The kind of transaction workload shown below needs to be sized to its peak to avoid impacting performance, but the cloud instance can’t be turned off during periods of lower utilization, so you will be paying for unused resource — a big waste.
Utilization patterns also impact instance selection and sizing. Consider some typical scenarios. Picture a workload that runs at 100% for 30 minutes every morning at 9 a.m., such as a start-of-day batch job. Ninety percent of the time it’s idle, so the daily average might be 5%. Or think about an SAP module that gets very busy for half a day once every quarter. Only looking at averages (or basing decisions only on recent activity) might lead you to conclude that the CPU and memory requirements are very low, and you will miss the peak demand every three months. Using averages, you will end up wildly over- or under-provisioning these apps depending on the timeframe used, impacting either performance or cost significantly.
One of the critical errors organizations make is reliance on tools that take a simplistic approach, such as using averages or percentiles, to size for the cloud. For example, AWS Trusted Advisor looks at daily utilization averages over a period of days. While this is informative, it doesn’t go far enough to analyze the intra-day and business cycle variability of workloads. To get AWS instance provisioning and management right you need to statistically model workload patterns in ways that look at hourly, daily, monthly, and quarterly activity.
How are you currently analyzing your cloud-based workload patterns? Do you have a view that is granular, while also studying behavior over long timeframes? Or are you missing some of those peaks and valleys?
In the next blog post, we’ll look at another common pitfall that we call the cloud instance bump-up loop.
More in this Series
This post is part of a series of five articles on how to reduce public cloud costs by choosing the right instances from public cloud vendors such as AWS, Azure, IBM, and Google.



