
In the first blog in this series, we looked at why it’s so important to look at an application’s workload patterns when sizing for any public cloud, including AWS, Microsoft Azure, Google Cloud Platform, and others. In this post, we’ll look at another common pitfall that we call the cloud instance bump-up loop.
Here’s how it works. You use a reporting tool that says your application workload is running at nearly 100% utilization for 3 hours overnight (see figure below).
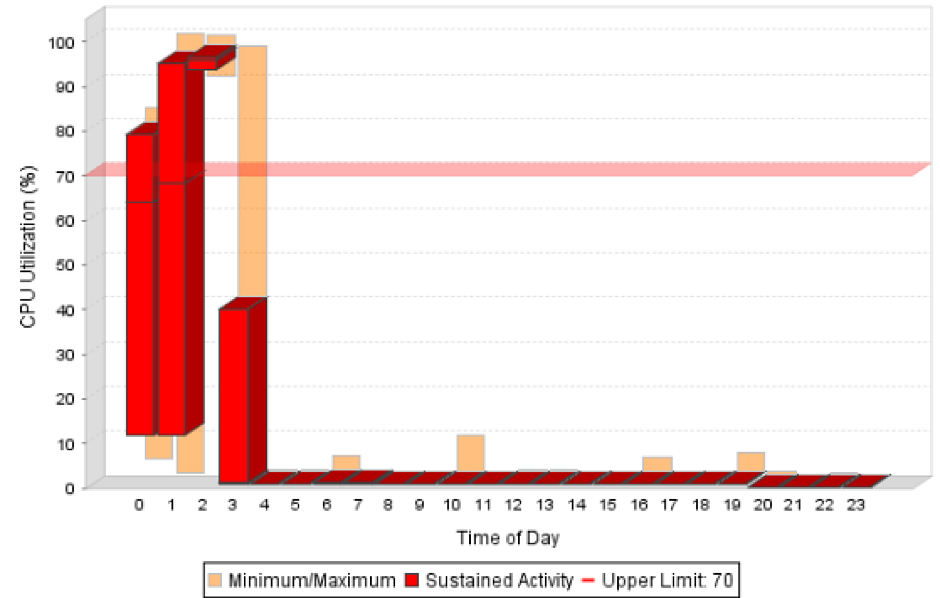
The tool is designed to interpret high utilization as bad, and concludes that the workload is under-provisioned. So it recommends bumping up the CPU resources, and in doing so increases your costs. But a funny thing happens: despite the change, the next day the workload still runs at 100%, just for a shorter period of time. Once again, tool says to throw more resources at it. The next day you see the workload still runs at 100%, but again for a shorter period of time. And so on. Now you’re stuck in the endless capacity bump-up loop.
Why? Because some applications will take as much resource as you give them. It’s kind of like how goldfish will just keep eating and never be sated. In public cloud, your costs keep escalating for little-to-no payoff.
To avoid this bump up loop, you need to understand what the workload is doing and how it behaves. In the example above, this batch job completed its work in 3 hours, which was completely satisfactory despite CPU being pegged at 100%. By giving it more processing resources, all you’ve done is increase your costs. Bigger gold fish with no business benefit.

People fall into the bump-up loop because they’re using simple tools that aren’t smart enough to recognize what’s really happening. It’s not enough just to take a high-level view of the workload usage. You also need to understand each individual workload pattern on a granular level. Some workloads running at 100% may need a larger instance to meet its requirements, while others — such as the example above — do not. Limited tools just can’t give you that insight.
If all you do is look at peaks or averages, and not the actual workload patterns, you’re bound to make decisions that end up costing you more — such as paying for a “large” AWS instance when all you really need is a medium. On the other hand, if you use tools that give you a deeper understanding of workload patterns and requirements, you can create policies to control allocations based on behavior, which will guide instance sizing to optimize your cloud resource spend and avoid the bump-up loop.
In the next blog post, we’ll look at another tricky issue: how to size memory for cloud instances. As with analyzing CPU use, analyzing memory use is not as simple as you might think.
More in this Series
This post is part of a series of five articles on how to reduce public cloud costs by choosing the right instances from public cloud vendors such as AWS, Azure, IBM, and Google.



