
What is Densify?
A 2 min intro to Densify
Densify automatically optimizes the compute resources of Kubernetes,
Cloud & AI workloads.
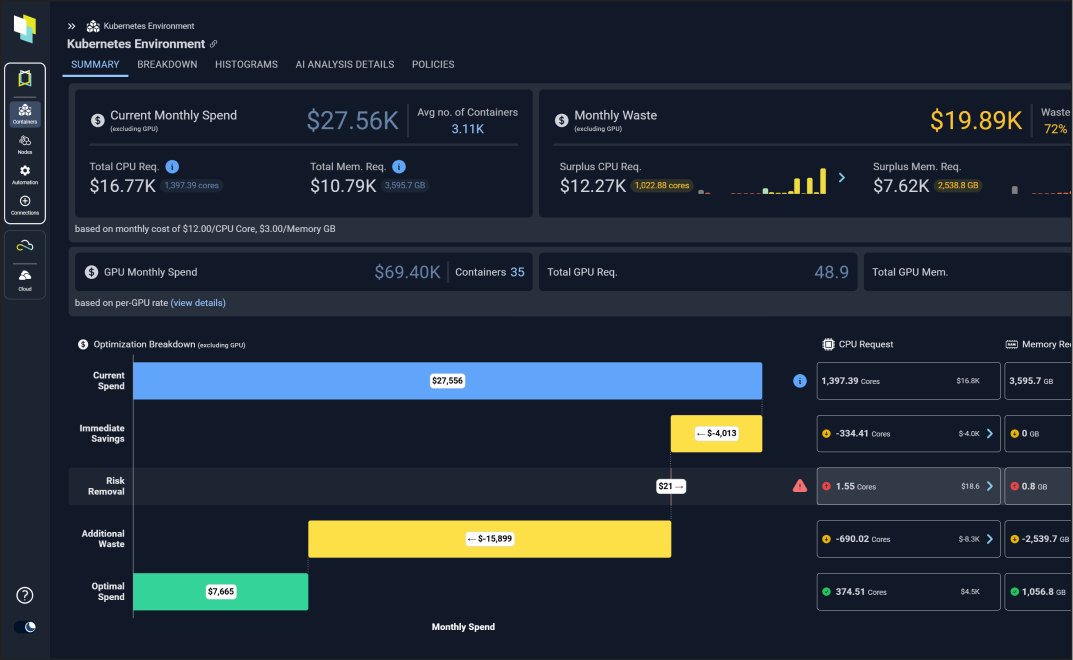
Fully Automate Kubernetes Resource Optimization with Kubex
Slash cost, improve reliability and spend less time managing:
- Automate using the most trustworthy recommendations on the market
- Easily share findings with others
- Machine learning of hourly patterns
- Kubex detects memory limit events and restarts and recommends increasing memory limits
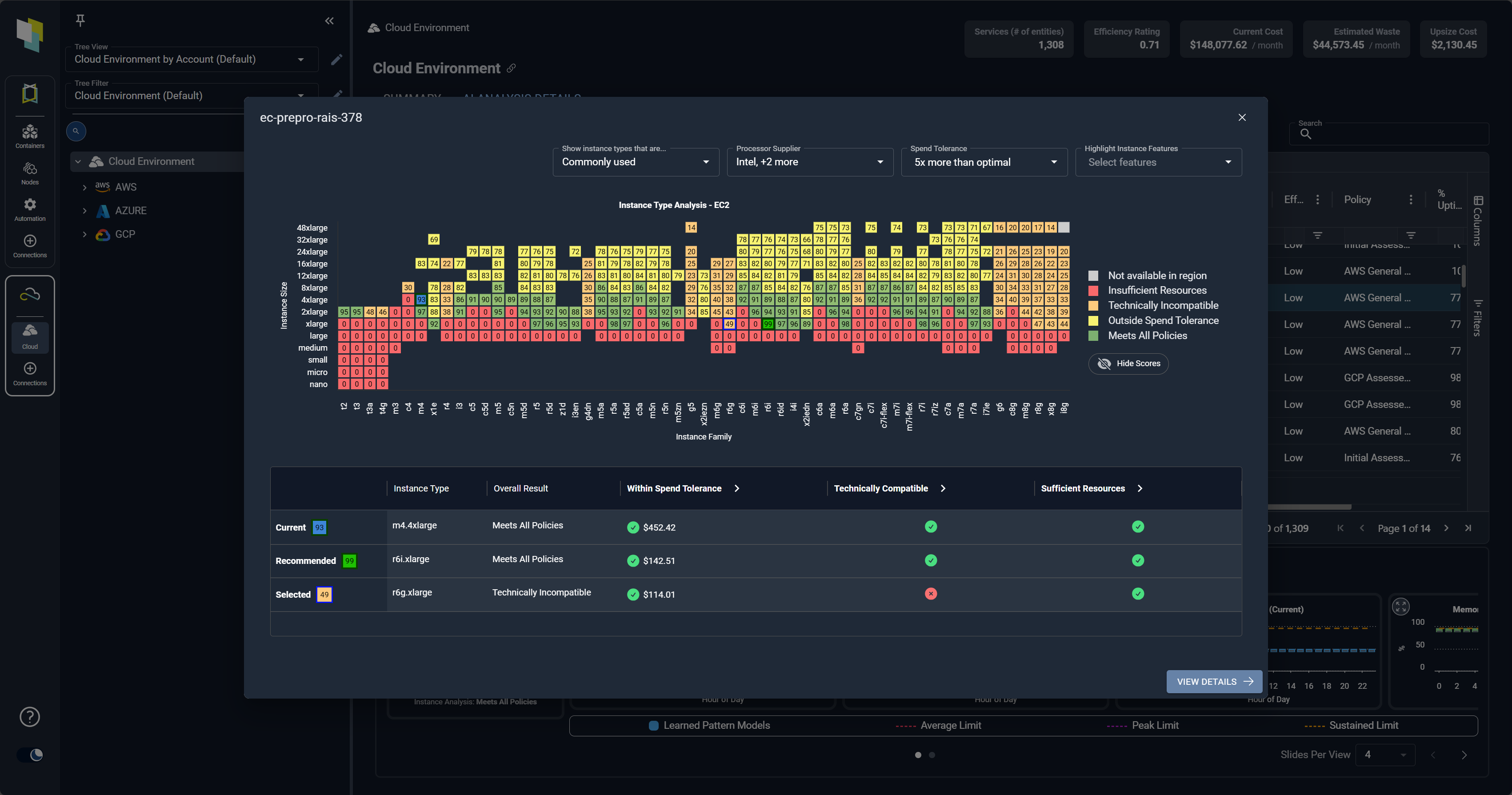
Select the Optimal Cloud Instance for Every Workload
Enabling FinOps Programs:
- Solve the single biggest issue for most FinOps programs – Accepting and actioning optimizations
- Cloudex Catalog Maps make the impact of decisions crystal clear and encourage the right choices
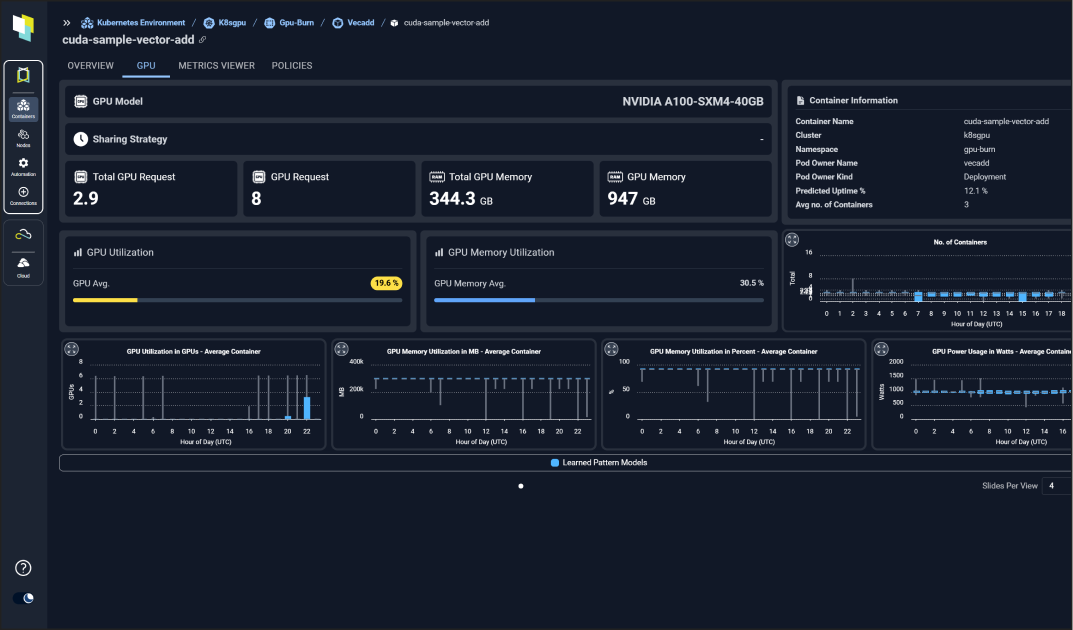
Optimize GPU Usage and Efficiency
Gain real-time and granular understanding of GPU usage and efficiency:
- Understand the utilization of every AI workload at every level of the stack
- Reclaim wasted capacity by evicting misplaced pods and recover idle or forgotten GPUs
- Real-time, predictive and adaptive insights: Continuously evaluate needs using AI-driven analytics.

See the benefits of optimized
Kubernetes Resources
AI-driven analytics that precisely determine optimal resource settings for Kubernetes.
[Video Transcript]
Densify is purpose-built SaaS software to optimize the resources of Kubernetes cloud and AI workloads. And one of the biggest things we see in Kubernetes environments is that they can be very expensive to run. And the root cause of this inevitably is that the requested limits are set wrong. Causing the Kubernetes scheduler to run too many nodes.
And even with the best node autoscaler and the best cloud discounts, if you’re running too much infrastructure, it’s going to be more expensive than it needs to be. So densify solves this by going to the root and analyzing all the container. Utilization patterns, replication patterns, and understands a deep policy to say what should they be set to?
And it then sets this automatically and automates the setting of these request and limits to make sure they’re aligned with the workloads. And the result is you not only save money, but also we see out of memory kills going down because we also upsize containers that have, for example, limits that are too low or requests that are too low.
And so the environment works better. It’s more elastic and you save a ton of money. Now, at the same time, we also optimize the cloud nodes that these things are running on. So maybe as you optimize, you can move to a memory optimize or a different type of instance, and it will do this automatically and it will auto program the scale groups and scale sets underneath the Kubernetes clusters.
Now we also do this for AI workloads. So if you have inference or training running on Kubernetes, we will analyze the workload patterns of the GPUs as well and the GPU memory, and we understand the containers and the relationship to the GPUs. What kind of GPUs they are, and we’ll recommend better settings to get better yield on those GPUs, including generating MIG plans and how you should divide up your GPUs so they’re more aligned with your workload.
And again, we see this in real environments, saves a ton of money because GPUs of course, are very expensive. Now in addition to optimizing the AI workloads, we also have a new AI interface into our analytics with a new MCP interface that lets you connect your favorite LLM into our analytics and ask very sophisticated questions and interact with it in a new way that doesn’t even require using the UI.
And so these things combined provide a very powerful way to both save money and save risk in Kubernetes cloud and AI environments.