
Implementing Resource Optimization Insights in a Red Hat OpenShift Environment Managed by Red Hat Ansible
Assume you have a process to determine the optimal settings for CPU and memory for each container running in your environment. Since we know resource demand is continuously changing, let’s also assume these settings are being produced periodically by this process. How can you configure Ansible to implement these settings each time you run the associated playbook for the container in question?
I don’t mean hardcoding the setting each time we’re ready to update—we’re looking for a scalable solution.
To answer these questions, we must first consider best practices for using declarative template driven tools like Ansible. Namely, that transient variables within the templates, should be surfaced out and managed as parameters in an external repository. These parameter repositories are key value stores typically implemented as NoSQL databases.
Aside from the obvious benefit of not having to modify the source templates whenever there is a change to one of the variables, the repo offers traceability, auditability and source control.
This means that the resource spec for a container, which is a set of transient variables, should not be specified in the Ansible playbook, but rather in a parameter repository. Therefore, we would need to find a way to modify the Ansible playbook to dynamically reference this repo at runtime, where presumably these parameters would exist.
The good news is that Ansible offers very flexible constructs like modules and plugins that we can take advantage of to not only deploy containers but also modify their resource specs after we identify more optimal settings.
Solution Components
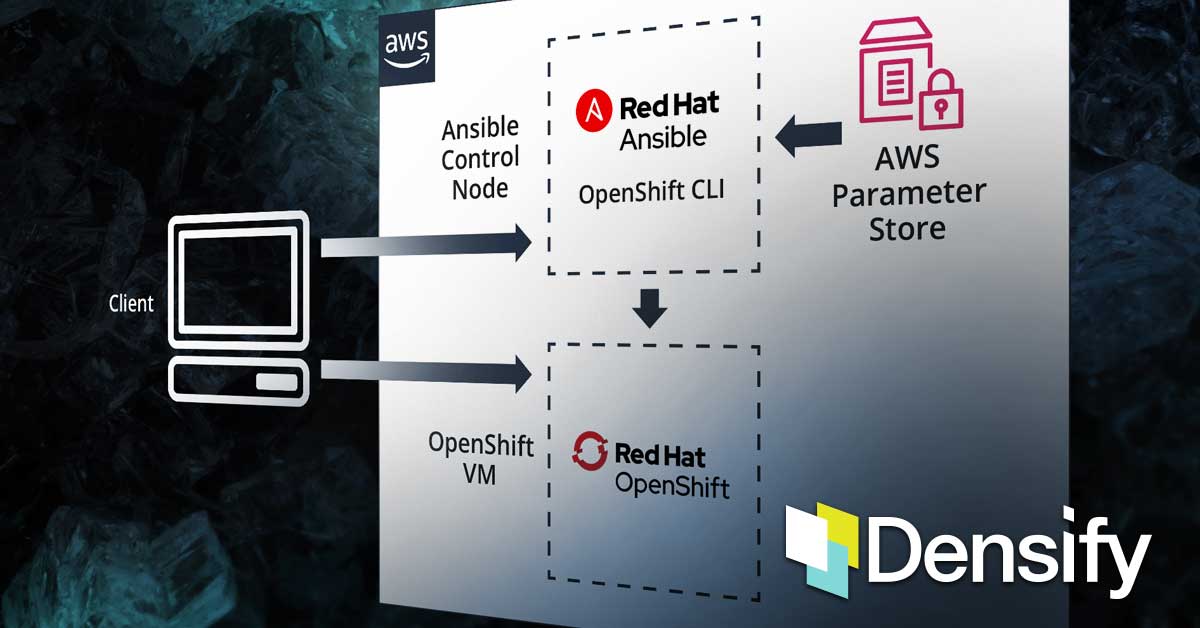
Here is a high-level interaction diagram of the solution components which we will implement in this tutorial. To keep things simple, we are going to stick to out-of-the-box prepackaged modules and plugins that are distributed with Ansible:

- Ansible
- The configuration management tool that we will use to deploy and manage containers in OpenShift
- k8s_auth
- Ansible module to authenticate to Kubernetes clusters which require an explicit login step
- k8s
- Ansible module to manage Kubernetes objects
- aws_ssm
- An Ansible lookup plugin that will get the value for an SSM parameter or all parameters under a path
- Red Hat OpenShift
- An open source container application platform based on the Kubernetes container orchestrator
- Parameter Repo
- Key-value store where our transient template variables will be stored as parameters. We will be using AWS Systems Manager Parameter Store for this tutorial
You’ll notice in the interaction diagram that a module (k8s) invokes a lookup plugin (aws_ssm) to extract parameters from AWS Parameter Store. As I mentioned before, the parameters we’re extracting are the optimal resource settings for the container(s) we’re interested in. It stands to reason that an obvious prerequisite is that the parameters should already exist in AWS Parameter Store.
Ways to analyze container workloads to derive optimal resource settings and delivery of those settings to your parameter repo is outside the scope of this tutorial, but Densify is able to help if you are looking for a solution that provides this capability.
The Sandbox
To help facilitate the demonstration, we’ll setup a sandbox environment comprising of an OpenShift installation and an extra VM to host Ansible. Earlier on I wrote a tutorial that you can use to get the Ansible environment up and running.

Ansible Installation Guide
We need to start by logging into the control node and validating the hostname and hosts file. It will simplify the Ansible configuration later on:
- Log into the control node using ssh:
$ssh <ip_address> - Update the hostname by editing the
/etc/hostnamefile. We will call this nodeansible_vm:$sudo su # echo 'ansible_vm' > /etc/hostname - Check if Ansible is already installed. If not installed install using the amazon extension packages:
$ansible --version
If installed, you will see the following output:ansible 2.9.5 config file = /etc/ansible/ansible.cfg configured module search path = [u'/home/ec2-user/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules'] ansible python module location = /usr/lib/python2.7/site-packages/ansible executable location = /usr/bin/ansible python version = 2.7.16 (default, Dec 12 2019, 23:58:22) [GCC 7.3.1 20180712 (Red Hat 7.3.1-6)] - If you don’t see the above output, then run this command to install Ansible. Check the version to confirm it’s installed:
$sudo amazon-linux-extras install ansible2 $ansible --version
As noted in the introduction, we are going to use two Ansible modules to deploy the container, k8s and k8s_auth, and an Ansible lookup plugin, aws_ssm, to enable dynamic references to Parameter Store.
These modules and lookup plugin are implemented in Python, and naturally, there would be package dependencies. If we navigate to each item, we can identify what those dependencies are. Alternatively, you can also find this information in the Ansible online documentation.
/usr/lib/python2.7/site-packages/ansible/plugins/lookup/aws_ssm.py
requirements: boto3, botocore
/usr/lib/python2.7/site-packages/ansible/modules/clustering/k8s/k8s.py
requirements: python >=2.7, openshift >= 0.6, PyYAML >= 3.11
/usr/lib/python2.7/site-packages/ansible/modules/clustering/k8s/k8s_auth.py
requirements: python >=2.7, urlib3, requests, requests-oauthlibIn order to install Python packages, we first need to install pip, the standard package management system used for Python.
- Check if pip is already installed:
$pip --version - If pip is not installed, then install it:
$sudo yum install python-pip - Check which packages are already installed:
$pip freeze - For each package that’s missing, install it:
$sudo pip install <package_name>
Be sure to verify all necessary packages are installed.
The lookup plugin only requires read only access to your SSM environment, however, since we will be inserting some parameters into Parameter Store in this tutorial, please make sure that we have a set of AWS credentials that have read/write access.
- Configure AWS credentials on the control node:
$aws configure
Now, we need to create a new cluster admin role that the Ansible modules will use to authenticate. We will need to execute these steps from the node where the OpenShift OC CLI tool is installed. If you followed the tutorial, How to Setup Minishift on a Standalone VM, then this tool will already be installed on your control node.
- Log into the node where the OpenShift CLI is installed:
$ssh <ip_address> - Login using your OpenShift credentials:
$oc login - Upgrade the account we will use to have cluster-admin privileges:
$ oc adm policy add-cluster-role-to-user cluster-admin admin --as=system:admin
Deploying a Simple Container with Fixed Resource Definitions
We’re going to use the playbook found in the appendix to deploy an openshift/hello-openshift app. The highlighted text in the sample playbook will need to be updated based on the specifics of your environment. Once you’ve made the necessary changes, copy the contents onto a file with a .yml extension on your control node. Also, take note that the resource spec for CPU and memory has been hardcoded in this example, which is typical for container environments.
- Run the Ansible playbook:
$ansible-playbook <name of playbook>.yml
You should see an output similar to this:
PLAY [ansible_vm] ******************************************************************************************************************************************* TASK [Gathering Facts] ************************************************************************************************************************************** [WARNING]: Platform linux on host ansible_vm is using the discovered Python interpreter at /usr/bin/python, but future installation of another Python interpreter could change this. See https://docs.ansible.com/ansible/2.9/reference_appendices/interpreter_discovery.html for more information. ok: [ansible_vm] TASK [Try to login to OCP cluster] ************************************************************************************************************************** ok: [ansible_vm] TASK [deploy hello-world pod] ******************************************************************************************************************************* changed: [ansible_vm] PLAY RECAP ************************************************************************************************************************************************** ansible_vm : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 - Validate that the container was successfully deployed and confirm the resources spec of the running object:
$oc get pods $oc describe pods
Deploying a Container with Dynamic References to Resources
Before we can dynamically reference AWS Parameter Store, we need to ensure the parameters exist. We can quickly insert some parameters into your AWS environment using CLI. If you have already created a parameter for each variable in the resource spec, skip step 1.
- We need to create 4 parameters:
cpu_request,cpu_limit,mem_request, andmem_limit:$ aws ssm put-parameter --name ‘/tutorial/cpu_request’ --value ‘250m’ --type String $ aws ssm put-parameter --name ‘/tutorial/cpu_limit’ --value ‘500m’ --type String $ aws ssm put-parameter --name ‘/tutorial/mem_request’ --value ‘128Mi’ --type String $ aws ssm put-parameter --name ‘/tutorial/mem_limit’ --value ‘256Mi’ --type String - We are going to insert dynamic references into your Ansible playbook by using the
aws_ssmlookup function. Open your playbook and edit the resource spec of the manifest:resources: requests: #cpu: 300m cpu: "{{ lookup('aws_ssm', '/tutorial/cpu_request' ) }}" #memory: 64Mi memory: "{{ lookup('aws_ssm', '/tutorial/mem_request' ) }}" limits: #cpu: 600m cpu: "{{ lookup('aws_ssm', '/tutorial/cpu_limit' ) }}" #memory: 128Mi memory: "{{ lookup('aws_ssm', '/tutorial/mem_limit' ) }}" - Re-run the ansible template and verify the resource spec within the running pods have been modified to conform with what’s specified in Parameter Store:
$ansible-playbook <name_of_playbook>.yml $oc describe pods
In this tutorial we discovered some best practices on how to deliver container resource insights through automation tools like Ansible. The approach we implemented made use of a parameter repository from which Ansible extracted insights at runtime. The repository enabled us to not only construct a scalable solution that didn’t the require continuous modification of existing templates, but also offered traceability, auditability and source control.
Appendix: Sample Ansible Playbook
- hosts: ansible_vm
tasks:
- name: Try to login to OCP cluster
k8s_auth:
host: https://<$openshift_ip>:8443
username: $username
password: $password
validate_certs: no
register: k8s_auth_result
- name: deploy hello-world pod
k8s:
state: present
apply: yes
namespace: myproject
host: https://<OpenShift_IP>:8443
api_key: "{{ k8s_auth_result.k8s_auth.api_key }}"
validate_certs: no
definition:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-openshift
labels:
name: hello-openshift
spec:
selector:
matchLabels:
app: hello-openshift
replicas: 1
template:
metadata:
labels:
app: hello-openshift
spec:
containers:
- name: hello-openshift
image: openshift/hello-openshift
ports:
- containerPort: 8080
protocol: TCP
resources:
requests:
cpu: 300m
memory: 64Mi
limits:
cpu: 600m
memory: 128Mi


