
Kubernetes gives you the amazing power to deploy and manage containerized applications. But this power comes with a trade-off. Instead of letting you focus only on writing code and delivering features, Kubernetes also shifts the burden of resource optimization i.e., cost control, performance, and scalability, directly onto your shoulders.
The answer to these challenges is automation. Automated optimization takes the guesswork out of resource allocation. By continuously monitoring usage patterns and automatically adjusting container settings, automation helps ensure that every workload gets just the right amount of resources. This means better performance, improved stability, and lower cloud bills- all without the manual effort.
The Kubernetes Resource Optimization Challenge
Manually configuring resource requests and limits for each container can lead to two common issues:
Overprovisioning: When you end up allocating too many resources to your containers. This means you might set the CPU requests and limits higher than what your application actually needs. While this might seem safe, it leads to wasted resources and higher cloud bills. You’re paying for extra capacity that sits idle most of the time.
Underprovisioning: If you set the resource limits too low, your application can struggle to perform under load. This can result in slow performance, application crashes, or even Out-of-Memory (OOM) errors. When containers don’t have enough resources, they cannot handle traffic spikes or complex computations, which leads to instability.
Why Does Manual Tuning Fail at Scale?
The manual configuring of resource settings might work for a small number of applications, but it quickly becomes unsustainable as your infrastructure grows. This is because:
- When you adjust resource requests and limits for every container by hand, it requires attention. As your number of containers increases, this process becomes both tedious and error-prone. For highly replicated containers, it’s almost impossible to tune them all by hand, as there’s too much data to process and too many instances to manage effectively without automation.
- The workloads in Kubernetes are not static. They change over time based on user demand and other factors. The manual tuning fails to keep up with these changes, meaning that what was once optimal can quickly become inefficient or even harmful when resources fall short of a workload’s requirements.
- The tuning resources for individual containers are just one piece of the puzzle. You also need to consider how these settings affect node performance and cloud instance selection. The interplay between container settings, node capacity, and overall cluster performance makes manual tuning a challenge.
The Need for Smarter, Scalable Methods
In dynamic Kubernetes environments, manual resource tuning becomes increasingly impractical. As applications evolve and workloads fluctuate, static configurations often lead to inefficiencies. To address these challenges, intelligent automation is essential. By using real-time analytics and adaptive algorithms, automated systems can continuously adjust resource allocations, ensuring optimal performance and cost-effectiveness.
The Role of Analytics
To effectively automate Kubernetes resource optimization, an understanding of the entire stack is essential. This involves analyzing the intricate relationships between various components such as CPU, memory, network I/O, and storage. These elements are deeply interconnected, and changes in one can significantly impact the others.
By continuously monitoring real-time metrics across the stack, intelligent tools can identify patterns and anomalies that may not be apparent through manual observation. This holistic visibility enables the detection of inefficiencies and the formulation of precise optimization strategies.
Platforms like Densify’s Kubex exemplify this approach by providing full-stack visibility into Kubernetes environments. It analyzes data from nodes to containers, offering actionable recommendations to reduce risk and waste for container compute resources. Kubex’s policy-based analytics engine produces precise and accurate resource optimization recommendations that, when implemented, enhance performance and cost-efficiency.
Why Automate?
Automation is more than just a trendy term; it’s the key to achieving efficiency while minimizing manual effort or oversight. When you automate resource optimization, you move from a reactive, error-prone process to a proactive, data-driven approach. Let’s break down why automating Kubernetes resource optimization is so important:
Increased Efficiency and Scalability: When you’re trying to guess (if that is even possible) the perfect CPU and memory allocation for each container, it can be a massive drain on time and resources. With automation, the system continuously monitors the resources your applications are actually using and adjusts resource settings in real-time. This means that whether you’re running a few containers or thousands, every container is always “right-sized” to meet its current demands. That’s how automation makes scaling seamless and efficient, making sure that your infrastructure adapts dynamically as workloads change.
Cost Control: A common challenge in Kubernetes is rampant overprovisioning, which results in unnecessary costs. Automated optimization uses real usage data to determine the exact amount of resources each container requires. By precisely tuning these settings, automation prevents both the waste of over-allocation and the risks associated with under-allocation. The result is a balanced system that provides just the right amount of power at the right time.
Reduced Manual Effort: The manual resource tuning not only takes up valuable time but also leaves a lot of room for human error. When you automate these adjustments, you eliminate the need for manual intervention. This frees your team from repetitive tasks, allowing them to concentrate on developing new features and improving your product.
Proactive Versus Reactive Management
Reactive Management: In the absence of appropriate feedback and automation, you may find yourself reacting to problems after they happen. This can result in unexpected downtime, user dissatisfaction, and increased costs.
Predictive Management: By using analytics and machine learning, it anticipates resource demands based on historical data and usage patterns. This predictive approach means proactively preventing issues before they occur, helping in smoother operations and consistent performance.
This predictive, continuous optimization approach operates behind the scenes to keep your environment running optimally.
Core Automation Strategies
Let’s discuss the different automation strategies that help in creating an optimized, self-healing Kubernetes environment:
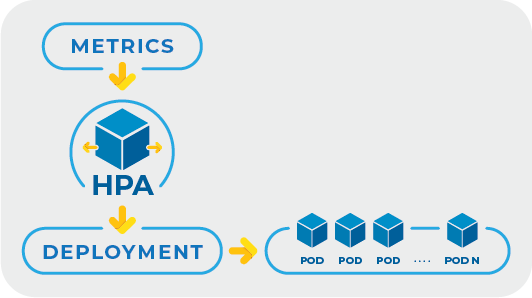
The Horizontal Pod Autoscaler (HPA) is one of the key building blocks for automating resource optimization in Kubernetes. It automatically adjusts the number of pod replicas in response to observed metrics like CPU utilization.
HPA works well in scenarios where workload patterns are predictable and primarily based on easily measurable metrics such as CPU or memory usage. In such environments, it scales your application up or down to match demand resulting in smooth performance while keeping costs under control. When combined with proactive monitoring, HPA plays a vital role in keeping your infrastructure responsive and resilient.
But HPA has its limitations. It adjusts the number of pods, but it doesn’t address the fine-tuning of resource requests and limits within each container. This means that even if your application scales correctly, individual containers might still be over- or under-provisioned. HPA depends on a narrow set of metrics, which may not capture the full complexity of your application’s performance needs. It can sometimes miss nuances like the effect of non-CPU-related workload changes, which results in inefficiencies or cost overruns.
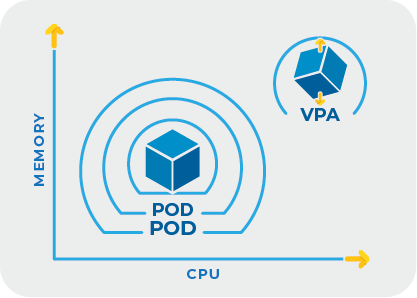
The Vertical Pod Autoscaler, or VPA, is designed to automatically adjust the CPU and memory settings of your containers based on their actual usage.
VPA continuously monitors your containers, keeping track of how much CPU and memory they actually use over time. Based on this data, it adjusts the resource requests and limits for each container. If a container consistently uses more memory or CPU than requested, VPA can increase those values; if it’s using less, VPA can scale them down.
Strengths of VPA
Data-Driven Precision: VPA uses real usage data to recommend or apply the ideal resource settings for your containers. This precision helps to ensure that each container is optimally sized.
Enhanced Performance: By adjusting resource allocations to meet the actual needs of the containers, VPA helps prevent situations where a container runs too slowly because it doesn’t have enough resources.
Risk Mitigation: VPA increase the resource sizes when containers face higher usage than initially allocated, helping mitigate the risk of resource shortages.
Risks and Limitations
Limited Historical Data for Recommendations: VPA doesn’t have a robust and reliable recommendation engine. By default, VPA uses only the last eight days of data to make recommendations. This constraint can hinder its ability to account for longer-term trends or demand patterns such as regular business cycles or seasonal traffic patterns.
Pod Restarts: One of the challenges with VPA is that making changes to a container’s resource settings requires the container to restart. These restarts, if not managed properly, can lead to temporary disruptions in your applications.
Note: While Kubernetes v1.33 introduced in-place pod resizing to address this issue, VPA does not yet support this feature. Consequently, resource adjustments via VPA still involve pod restarts. But you can do manual resizing of pods in-place. Integration of in-place resizing with VPA is under development.
Not a Silver Bullet: VPA focuses on fine-tuning individual containers. It does not capture broader scaling needs across the entire cluster. In some cases, this means that while each container is better sized, the overall application might still face challenges that require additional scaling strategies.
Complexity in Dynamic Environments: In environments with very dynamic workloads, frequent adjustments might lead to instability if the changes are too aggressive.
Conflicts with Horizontal Pod Autoscaler (HPA): When combining VPA with HPA, it requires careful consideration. If both autoscalers act on the same metrics, such as CPU or memory, they can interfere with each other’s operations. For example, VPA’s adjustments to resource requests can disrupt HPA’s scaling logic, resulting in unstable scaling behavior or even infinite scaling loops.
Due to these considerations, VPA is generally not recommended for production environments, especially those that are large-scale, dynamic, or require high availability.
Cluster Autoscaler
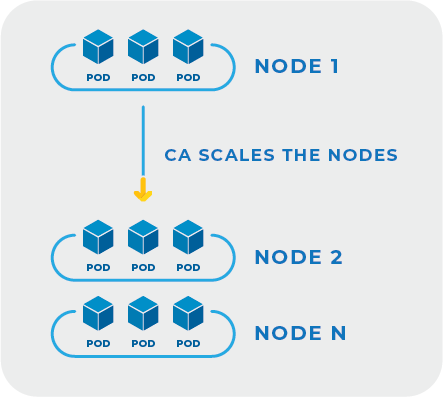
The Cluster Autoscaler is an important tool in the automation toolbox that dynamically adjusts the number of nodes in your Kubernetes cluster. It constantly watches your cluster for any signs of congestion or underutilization. When there are too many pending pods that cannot be scheduled due to insufficient resources, the Cluster Autoscaler automatically adds more nodes. And when it detects that some nodes are underused for a while, it can safely remove them to save costs.
This mechanism plays an important role in aligning your infrastructure with your actual workload needs. By ensuring that your cluster only runs as many nodes as are necessary, it helps to improve overall efficiency and control cloud spending.
Limitations
While the Cluster Autoscaler is excellent for managing node numbers, it does have its limitations. It doesn’t fine-tune the resources of individual containers; its focus is on the broader node level. This means that although your cluster can expand or contract based on demand, some containers might still be over- or under-resourced. For a fully optimized environment, the Cluster Autoscaler needs to work together with other automation tools that handle container-level adjustments.
Karpenter
Karpenter is an open-source tool that automates node provisioning in Kubernetes. Like the Cluster Autoscaler (CA), it monitors for pods stuck in a pending state and adds nodes to accommodate them. However, Karpenter is more tightly integrated with cloud provider APIs, enabling it to provision resources more rapidly than CA.
Karpenter selects the most suitable instance types based on the specific CPU, memory, and GPU requirements of pending pods. This flexibility allows it to efficiently match workloads to the right compute resources, reducing costs by avoiding overprovisioning. Karpenter also supports spot instances and has strong node consolidation capabilities, removing underutilized nodes and consolidating workloads to optimize resource usage.
Risks & Limitations
Limited Workload Awareness: Karpenter works only at the node level and does not adjust individual pod resource requests. It assumes that the pod specifications are accurate and does not account for workload-specific behaviors, which can lead to inefficiencies if pods are not properly configured.
Resource Request Accuracy: Karpenter provisions nodes based on the resource requests specified by pods. If these requests are overestimated, it can lead to unnecessary node provisioning, increasing costs and resource wastage. Conversely, underestimation can result in performance issues due to insufficient resources.
Spot Instance Interruptions: While Karpenter supports the use of spot instances to reduce costs, these instances can be terminated with little notice. Without proper configuration of AWS’s Spot Interruption Queue and necessary permissions, applications may experience abrupt shutdowns.
Policy-Based Controls
Policy-based controls are important for automating Kubernetes resource optimization, serving both as enforcement mechanisms and as governance frameworks that guide automation tools. The tools like Open Policy Agent (OPA) and Kyverno act as policy engines that enforce predefined rules on resource configurations and deployments. They continuously evaluate changes within the cluster, ensuring that any modifications adhere to established policies. For example, if a proposed change risks overprovisioning or violates security standards, these tools can block the change or trigger alerts.
Beyond enforcement, policies also play a critical role in controlling the behavior of automation tools. For example, mutating admission controllers can automatically adjust resource requests and limits during pod creation. However, without proper policy governance, such automation could lead to unintended consequences, like resource overallocation or conflicts with other scaling mechanisms.
By defining detailed policies, organizations can set boundaries for automation tools, specifying conditions under which certain actions are permissible. This ensures that automation aligns with organizational standards and operational requirements.
For example, Densify Kubex’s Mutating Admission Controller acts based on recommendations that are the result of detailed policies that govern recommendations, and in turn, automation actions, ensuring that resource adjustments are both safe and aligned with organizational objectives and constraints. This approach reduces risk by leaving customers in complete control of what automated actions are taken and how.
AI-Driven Platforms for Kubernetes Resource Optimization
AI-driven platforms bring an extra level of refinement to Kubernetes resource optimization. These platforms analyze historical and real-time usage data to detect patterns and predict future resource needs. They learn how your applications behave over time and then automatically fine-tune resource allocations to ensure every container, node, and cluster operates at its peak efficiency.
By continuously crunching data, an AI-driven platform can uncover hidden inefficiencies that manual tuning or traditional autoscaling methods might miss. This proactive approach not only helps in achieving the right balance between performance and cost but also minimizes the need for human intervention.
The result is a Kubernetes environment that scales smoothly, runs more predictably, and controls costs more effectively, all while reducing the manual effort required to manage the system.
Vendor Automation Approaches
When it comes to automating Kubernetes resource optimization, there are a number of vendors that offer capabilities but with significant variety in approacheslway. Let’s look at some of the strategies employed by a spectrum of vendors:
CI/CD & GitOps: Imagine that when an automated tool detects a rightsizing opportunity, it automatically submits a pull request to implement the change. With CI/CD and GitOps integration, these pull requests use your existing change management processes, ensuring that recommended adjustments are seamlessly incorporated into your deployment pipeline. This approach means that instead of simply checking if your resource settings are optimal when you update your code, the system actively manages resource adjustments in the background, keeping your infrastructure continuously updated with the most efficient configuration.
However, implementing this level of automation requires that application owners and developers grant access to their source code repositories. In practice, this is challenging due to security concerns, organizational policies, and the desire to maintain strict control over application codebases. Many teams are hesitant to allow external tools or automation systems to interact directly with their repositories, especially when it involves write permissions.
To address these concerns, a common best practice is to separate application source code from deployment configurations by maintaining distinct repositories. This separation allows infrastructure and operations teams to manage deployment manifests and configurations independently, without requiring direct access to the application code. Tools like Argo CD support this model by enabling synchronization with dedicated configuration repositories, thereby respecting the boundaries set by application teams while still facilitating automated deployments.
Admission Controllers: Admission controllers work behind the scenes as your containers are deployed. They intercept deployment requests and can immediately adjust resource settings in real-time, making sure that every container that starts running is correctly sized according to current workload demands. This immediate, on-the-fly correction minimizes the chance of misconfigurations slipping through, helping to maintain optimal performance and stability without requiring manual tweaks. When combined with AI-driven analytics, this becomes an even more powerful approach, ensuring resource settings are not only corrected in real time but also intelligently predicted and optimized based on workload behavior. It’s this combination, admission control plus AI, that forms one of the most effective automation strategies in Kubernetes.
Operators & Agents: Operators and agents take automation a step further by running within your cluster to perform closed-loop tuning. They continuously monitor the environment and automatically apply adjustments based on real-time metrics. This means that your system is constantly self-correcting, if a container starts using more resources than needed, or if there is unused capacity in your node utilization, the operator makes the necessary changes to keep everything balanced and efficient.
Human-in-the-Loop: Even in highly automated environments, there are times when a human touch is necessary. These workflows integrate approval processes and interactive interfaces, such as notifications or dashboard alerts, allowing engineers to review and authorize changes. For example, when an automated system detects that a container’s resource allocation requires adjustment, it can send an alert through Slack or update a dashboard with a detailed recommendation. This approach ensures that while the system does most of the heavy lifting, critical decisions can still be overseen by a person, adding an extra layer of safety and customization when needed.
API-Orchestrated Automation: Finally, API-orchestrated automation ties everything together by integrating optimization recommendations directly into your custom pipelines. With this method, your existing tools and workflows can automatically query the optimization engine, receive updated resource settings, and apply these changes as part of the deployment process. This integration ensures that your automation strategies work together, enhancing overall efficiency, scalability, and cost control.
Vendor K8s Automation Comparison
| Automation Capability | Densify | Cast.ai | PerfectScale | Sedai | ScaleOps | StormForge |
|---|---|---|---|---|---|---|
| Container Sizing Automation | ✔ Mature; accurate; configurable cost and risk policies, Supports several automation strategies) |
✔ Immature; cost-focused; supports MAC & GitOps; AI-based repo scraping; can be error-prone |
✔ Risk-focused; automation available |
✔ API-based; supports Terraform and GitOps |
✔ Supports K8s API & GitOps; repo scraping(error prone); overrides scheduler for bin packing |
✔ Recommendations only; manual GitOps required; uses Kustomize overlays |
| HPA Compatibility | ✔ Works with HPA; avoids inducing runaway scaling |
✔ Replaces HPA with custom autoscaler; memory-only; potential for runaway scaling |
✔ Appears functional based on feedback |
✔ Replaces with custom autoscaler; configurable metrics and thresholds |
✔ HPA-friendly; estimates scaling threshold |
✔ Provides HPA scaling recommendations; no automation |
| Node Autoscaling (ASG/ScaleSet) | ✔ Integrated scale group/set analysis and automation |
✘ Supports custom autoscaler only |
✔ Claims Suggests node sizes; no evidence of automation |
✔ Supports public cloud recommendations; no automation |
✘ | ✘ |
| Karpenter Node Optimization | ✔ CQ2; Auto-programs Karpenter allowed instance list using cloud catalog map |
✘ Competes with Karpenter |
✘ | ✘ | ✘ | ✘ |
| VM-Based Node Support | ✔ Visibility and analysis of VMs & ESX hosts underpinning K8s |
✘ | ✘ | ✘ | ✘ | ✘ |
| Dynamic Node Autoscaling | ✘ | ✔ Main focus; replaces native autoscaler |
✘ | ✘ | ✘ | ✘ |
Densify’s Kubex Platform: A Full Stack, Mutating Approach to Kubernetes Resource Optimization
Densify’s Kubex platform delivers a full-stack approach to Kubernetes resource optimization; intelligently linking workload performance with underlying node infrastructure. It goes beyond cost savings by ensuring optimizations result in realizable gains without introducing risk. Kubex analyzes heavily replicated services and dynamically tunes both container sizing and node selection based on deep policy controls and actual usage. It features a Mutating Admission Controller that safely injects optimal resource settings at deployment time, helping teams enforce consistency without manual intervention.
The platform provides deep linking between recommendations and the data that justifies them, giving platform owners confidence to take action. Kubex is designed to work alongside existing autoscalers and offers flexible integration with tools like HPA and Karpenter, enhancing them rather than replacing them. With real-time visibility across both application and infrastructure layers, Kubex helps Kubernetes teams automate safely- improving cost, performance, and stability without compromising control.
Factors in Workflow Integration
When automating Kubernetes resource optimization, different factors come into play to ensure smooth deployment and continuous improvement. These factors are:
Rollout Models: Canary and Blue/Green Deployments
The effective deployment strategies are important for minimizing risks associated with releasing new application versions. The two widely adopted models are:
Canary Deployments: This approach introduces the new application version to a small subset of users before a full rollout. By directing a fraction of the traffic to the updated version, teams can monitor its performance and stability in a real-world environment. If issues arise, the impact is limited, allowing for quick rollbacks. Once confidence is established, the deployment can be expanded to the broader user base.
Blue/Green Deployments: This method involves maintaining two separate environments: one hosting the current stable version (blue) and the other containing the new version (green). The traffic is initially directed to the blue environment. When the green environment is ready and tested, traffic is switched over seamlessly. This strategy reduces downtime and provides a straightforward rollback plan if needed.
Feedback Loops: You should integrate continuous feedback loops into the deployment pipeline. It is vital for early issue detection and ongoing improvement that enable teams to promptly identify and resolve problems, ensuring that only high-quality code advances through the pipeline. This iterative process encourages collaboration, keeps the team aligned with project goals, and cultivates a culture of continuous learning and adaptation.
Policy Guardrails: Simultaneously, implementing policy guardrails ensures that all deployments adhere to organizational standards and security policies. The tools like Open Policy Agent (OPA) and Gatekeeper work within Kubernetes to define and enforce custom policies that help prevent misconfigurations and maintain compliance.
At the infrastructure level, policy-based automation remains critical and this is where Kubex brings unique value. Our platform extends policy-driven guardrails to the cloud instance layer, ensuring that nodes are intelligently selected and right-sized to match workload demands. This proactive approach minimizes waste and enhances cost efficiency, empowering organizations to optimize their infrastructure effectively.
Potential Pitfalls
Here are some common pitfalls to watch out for when implementing autoscaling in your Kubernetes environment:
Misunderstanding Autoscaling
The autoscaling in Kubernetes involves dynamically adjusting resources to meet application demands. This includes scaling pods horizontally with the Horizontal Pod Autoscaler (HPA) and nodes with the Cluster Autoscaler (CA) as we discussed above. A common misconception is assuming that enabling autoscaling will automatically optimize performance without proper configuration. For example, HPA relies on accurate metrics and appropriate thresholds to function effectively. Without fine-tuning these parameters, you may experience inadequate scaling, leading to performance bottlenecks or resource wastage.
Over-Reliance on CPU Metrics
You have seen that many autoscaling configurations default to using CPU utilization as the primary metric. While CPU usage is an important indicator, overemphasizing it can lead to suboptimal scaling decisions. The applications may be constrained by other resources such as memory, disk I/O, or network bandwidth. When you rely solely on CPU metrics, it can result in scenarios where pods are scaled inappropriately, either over-provisioning resources or failing to meet actual application needs. You should incorporate a diverse set of metrics that reflect the application’s resource consumption and provide a more balanced and effective autoscaling strategy.
Git as the Source of Truth
In GitOps practices, Git repositories serve as the definitive source for infrastructure and application configurations. The direct manual changes to the Kubernetes cluster that bypass Git can lead to configuration drift, where the live environment deviates from the version-controlled source. This weakens the reliability and traceability of deployments, complicating troubleshooting and rollbacks. You should ensure that all changes are committed to Git and propagated through automated pipelines to maintain consistency and alignment with GitOps principles.
Lack of Transparency and Developer Context
The effective optimization requires clear visibility into how scaling decisions are made and their impact on applications. A lack of transparency can leave development teams uncertain about the behavior of their applications under varying loads. You should provide developers with insights into autoscaling policies, thresholds, and real-time metrics to foster better understanding and trust in the system. Also, you should involve developers in defining autoscaling parameters to ensure that the configurations align with application performance characteristics and business requirements.
Conclusion
Now, you can see that transitioning from manual tuning to autonomous efficiency marks a great milestone in managing Kubernetes environments. When you rely on automation, you free your team from endless manual adjustments and the constant guesswork involved in setting CPU and memory values. Instead, your system continuously learns from actual usage patterns and adapts in real-time. This means your applications run more efficiently, scale seamlessly, and cost less over time.
Automation is not about replacing the expertise of platform engineers, it’s about empowering them. With automated optimization handling routine tasks, your team can focus on higher-level strategy and innovation. The engineers remain in control, using automation as a powerful tool that enhances their ability to deliver robust, high-performing applications.
Looking ahead, the next steps would be evaluating the various automation tools available, piloting automation paths in controlled environments, and establishing strong feedback loops. This approach allows you to continuously refine and improve your processes, ensuring that every change brings measurable benefits. You should embrace automation, which not only reduces manual effort but also creates a more resilient, scalable, and cost-effective infrastructure for the future.
Want to extract the maximum potential from your Kubernetes Infrastructure? Start your free trial today with Kubex by Densify.
Learn major trends across major cloud providers such as Amazon Web Services (AWS), Microsoft Azure Cloud and Google Cloud Platform (GCP). Read this article Public Cloud IaaS Catalogs Update.



