Enterprise Management Associates (EMA) research shows that approximately 50% of public cloud customers are complaining about significant cost overruns in their monthly public cloud bills. 36% indicate that they only have an incomplete understanding of public cloud cost and 38% admit that they are not able to predict public cloud performance and compliance. The fact that enterprises are expected to place an additional 19% of their current on-premise workloads into a public cloud over the following 12 months further increases the severity of the public cloud cost challenge.
Public Cloud Pricing: Is it Purposefully Complex?
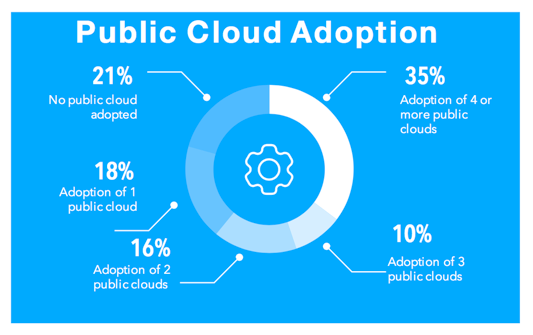
Understanding the pricing models and SLAs of public clouds is a difficult job, due to the dozens and in case of Azure and AWS even over 100 service offerings. Public cloud providers make the situation more difficult by offering region-specific pricing, SLAs and services. Additionally, customers need to decide whether they want to pay as they go or select reserved instances and they need to consider the cost of shoveling data to and from a public cloud and the additional network traffic generated by dependencies on data from applications hosted in different locations. And finally, enterprises need to consider whether there is a more cost-efficient solution -public or on-premise- for the specific application. The fact that 35% of enterprises already have adopted 4 or more public clouds makes this situation even more complex.

Really? 35% of Enterprises Have Adopted 4 or more Public Clouds?
This number may seem stunning, but when you think about that development teams like to compose their applications from different best of breed solutions this makes a lot of sense: grab Google’s Tensorflow for machine learning, use Amazon Lambda for your functions, host your SAP on Virtustream and leverage Azure because it’s part of your Microsoft ELA anyway.
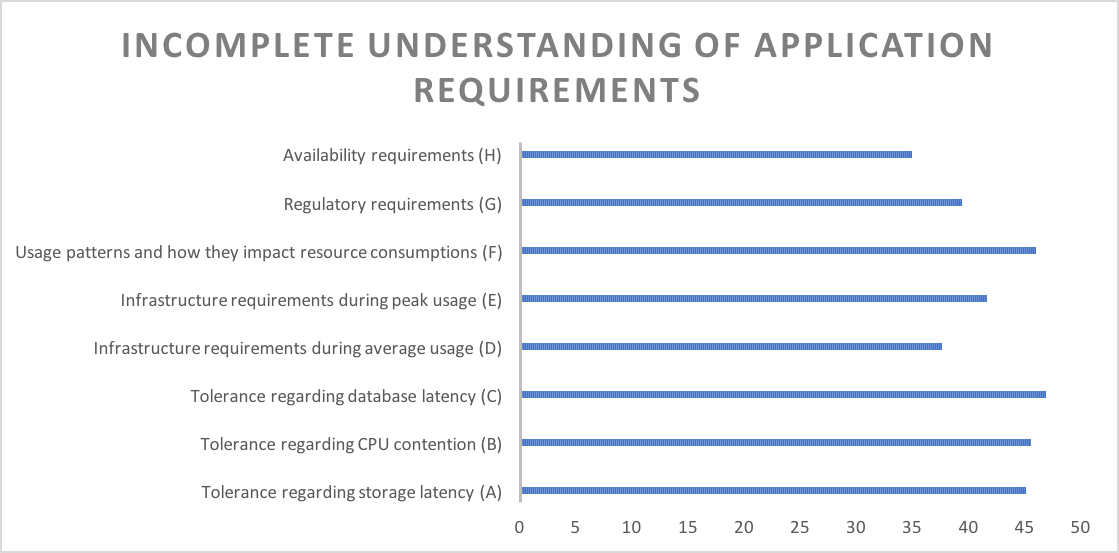
Incomplete Understanding of Application Workloads – The Root of all Evil
When investigating into organizations’ understanding of application requirements we found that these specifications are typically incomplete when it comes to the finer, but critical, details in terms of performance and compliance. For example, only about half of enterprises can answer questions like “how much database latency can your application stomach while still delivering acceptable response times” or “how much network traffic does your app generate during peak times.” Matching workloads you do not fully understand with a public cloud is tricky.
Automation The Forgotten Discipline
Automation silos and a flat-out lack of automation were the key root cause of OpenStack never reaching its full potential and they are also responsible for significant risk introduced through public cloud lock in. To prevent cloud lock-in (82% of organizations indicate that cloud lock-in is a bad thing), you must attach your automation to the application layer. This means that you define deployment, configuration, monitoring, scalability and management requirements independently of your specific compute, storage, security, compliance, OS, middleware and network infrastructure. This application-centric automation approach is the foundation for optimizing risk and cost of application placement by optimizing placement.

What Does this All Mean to Me? How Do I Balance Risk and Cost?
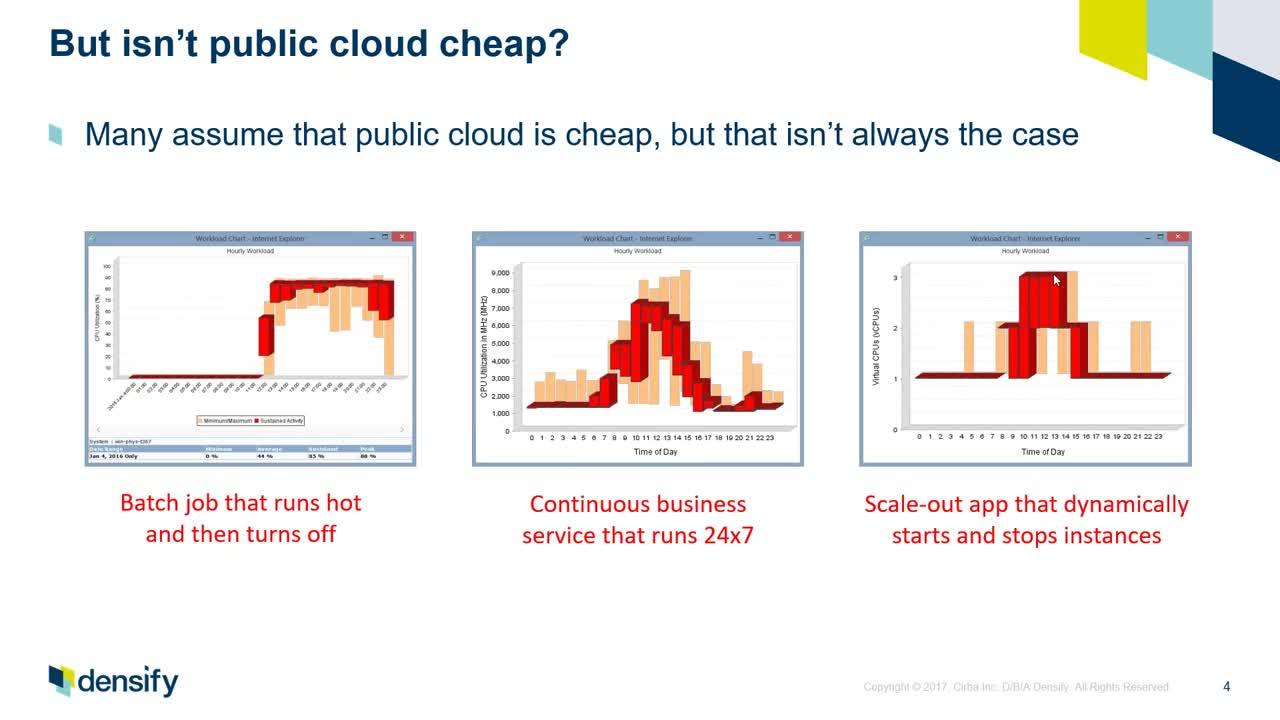
Exactly understanding when your application workload uses how much storage, network and compute is not a trivial task, as this depends on how end users interact with this application over time. For example, a certain network bandwidth between servers can be just fine 99% of the time, but on Black Friday every customer transaction takes 3 times as long as usual, due to exponentially increasing database traffic.
But even if you fully understand your workload requirements, how do you exactly match them to your various hosting options, including on-prem vSphere or Hyper-V? How do you figure out if deployment to VMs, containers, serverless functions or bare metal makes the most sense?
Of course, you have to also factor in dependencies on data, services and other apps that can cause performance challenges and you will want your entire organizations to benefit from the learnings of your research.

At the end of the day, this is not a job for a human, as there are way too many constantly fluctuating data points. It’s a job for advanced analytics and machine learning. You basically need a collective and continuously learning brain.
Recorded Presentation with EMA: 3 Ways to Reduce Amazon Web Services & Microsoft Azure Costs
Watch Video



