Deploying the Data Forwarder with Authenticated Prometheus
Deploying the Data Forwarder with Authenticated Prometheus
#410180
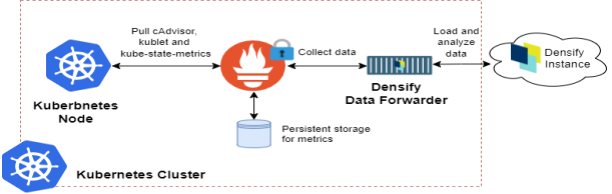
This topic shows you how to configure the data forwarder with an authenticated Prometheus server for data collection using YAML files for a single cluster. By default, the Prometheus server is secured when it is part of Red Hat OpenShift deployment. Therefore, the instructions in this topic use the OpenShift CLI for configuring the data forwarder with the authenticated Prometheus server.
After deploying the data forwarder, contact [email protected] to enable your Densify instance with container optimization.
Deploying the Data Forwarder
Before you begin, ensure you have met all of the prerequisite software and configuration requirements. See Container Data Collection Prerequisites.
- Navigate to: https://github.com/densify-dev/container-data-collection/tree/main/single-cluster/examples/bearer-openshift and save the following files to your local working directory:
- clusterrole.yaml
- clusterrolebinding.yaml
- configmap.yaml
- cronjob.yaml
- pod.yaml
- serviceaccount.yaml
- Edit the configmap.yaml. See the table below for details of the settings.
- You need to create the service account, cluster role, and cluster role binding before testing the data forwarder functionality in your cluster. The additional, required configuration is provided in the readme on Densify's github page.
- Once the data forwarder is able to send the collected container metrics,
|
|
|
Note: Save the raw version of the files to avoid any unwanted characters (i.e. click on the top right Raw button from the GitHub text viewer to open the raw text file in a new browser tab, then save the file to your local working directory).
Configuring the Data Forwarder Using configmap.yaml
- Open configmap.yaml and provide connectivity details for Densify, Prometheus and identity details for all of the clusters to be analyzed. See the table below for details of the required settings.
- Once you have updated the files with your settings, then place it in the CLI working directory from where you manage your clusters.
Table: Data Forwarder Settings in configmap.yaml
|
Term |
Description |
Value |
||
|
Forwarder Configuration |
||||
|
scheme |
Specify the protocol to be used to connect to the Densify REST API interface. Select http or https. |
https |
||
|
host |
Specify your Densifyinstance details (e.g. myCompany.densify.com). You may need to specify Densify IP address. |
<host> |
||
|
port |
Specify the TCP/IP port used to connect to the Densify server. You should not need to change this port number. |
443 |
||
|
username |
Specify the Densify user account that the Data Forwarder will use. This user must already exist in your Densify instance and have API access privileges. Contact [email protected] for the Densify user and epassword required to connect to your Densify instance. This user will be authenticated by the Densify server. |
<user name> |
||
|
password |
Specify the password associated with the user indicated above. Specify the password in plain text. |
|
||
|
encrypted_password |
Specify encrypted password for the user indicated above. The password must be encryptedand supersedes any value that has been specified in the password field, above. Typically, [email protected] will provide a Densify username and corresponding encrypted password when they setup your Densify instance container data collection. Ensure the password line is commented out if it is not used. |
<encrypted password> |
||
|
endpoint |
This is the connection endpoint for the API. You can leave the default value. |
/api/v2/ |
||
|
retry |
The retry settings are optional and if not set specifically, then the default values are used. See Configuring Retry Connection Attempts for setting details. |
|||
|
proxy |
If you need to configure data collection through a proxy server, see Configuring a Proxy Host. |
|||
|
prefix |
Specify a prefix for the compressed filename. |
<zip file prefix> |
||
|
Prometheus Configuration |
||||
|
scheme |
This is set ot https. Do not change the value or uncomment the setting. |
https |
||
|
host |
Specify the Prometheus hostname. In this configuration the data forwarder is not deployed in the same cluster as Prometheus, so you may need to specify a fully qualified domain name. i.e. https://<AWS region>.console.aws.amazon.com/prometheus/home?region=<AWS region>#/workspaces/workspace/<AMP workspace ID>
|
<Prometheus host> |
||
|
port |
Specify your Prometheus service connection port. The default port is 9090. |
9090 |
||
|
username |
Specify the Prometheus basic authentication username that the Container Optimization Data Forwarder will use to connect and collect data. This user must be setup on your Prometheus server and have the required access privileges. |
<username> |
||
|
password |
Not used for this configuration. |
<password> |
||
|
encrypted_password |
Not used for this configuration. |
<encrypted password> |
||
|
bearer_token |
Bearer token can be used for a number of solutions supporting Prometheus-API. It is required by OpenShift Monitoring. See: https://access.redhat.com/documentation/en-us/openshift_container_platform/4.14/html/monitoring/accessing-third-party-monitoring-apis The value of this parameter may be either the token itself or the name of file containing the token. |
<token | path> |
||
|
ca_cert |
Enable this parameter (i.e. uncomment this line) if you are using SSL. If enabled then specify the path to the certificate: /var/run/secrets/kubernetes.io/serviceaccount/service-ca.crt |
<certificate | path> |
||
|
sigv4 |
Not used for this configuration. |
|
||
|
retry |
The retry settings are optional and if not set specifically, then the default values are used. See Configuring Retry Connection Attempts for setting details. |
|
||
|
Collection Settings |
||||
|
Indicate which entity types for which data should be collected. This section is optional and if not set or empty then all of the following entity types are included.
|
true |
|||
|
interval |
Optional: Specify the interval at which to collect data. Select one of days, hours or minutes. If you make changes here these interval settings must correspond with cronjob settings. |
minutes |
||
|
interval_size |
Optional: Specify the interval at which data is to be collected. If the interval is set to hours and interval_size is set to 1, then data is collected every hour. These interval settings need to correspond with your cronjob settings. |
1 |
||
|
history |
Optional: |
0 |
||
|
offset |
Optional: Specify the number of days, hours or minutes (based on the interval value) to offset data collection, backwards in time. |
0 |
||
|
sample_rate |
Optional: Specify the rate at which to collect samples within the specified interval. i.e. if the interval_size is set to 1 hour and sample rate is 5 seconds, then every hour 12 samples are collected. |
5 |
||
|
node_group_list |
Optional: Specify a nodegroup label reference. By default, the "node_group_list" parameter is commented out and the data forwarder use the values, listed:
If you want to specify a node group label that is not included in the following list, uncomment this parameter and specify your node group label. See Configuring Node Group Collection for more details. |
|
||
|
name |
In a multi-cluster configuration, each cluster must have a unique name as well as a set of unique identifiers for each cluster. |
<name of first cluster> |
||
|
identifiers |
Specify identifiers as a map of Prometheus labels (name and value) to uniquely identify the cluster. If you omit the identifiers, only one cluster can be present in this list. |
<label name>: <label value> |
||
|
debug |
Use this setting to turn debugging on/off. |
<false> |
||
Note: Deploying and scheduling the data forwarder can also be accomplished using the Red Hat OpenShift Container Platform console. The steps to deploy the data forwarder in the OpenShift console are similar to the kubectl commands.